Páni, jsem na řadě, abych vrhl nějaké ponuré světlo na iptables! Na toto téma existují stovky nebo dokonce tisíce článků, včetně těch úvodních. Nebudu sem dávat formální a nudné definice ani dlouhé seznamy užitečných příkazů. Než se pustím do všech těchto tabulek, pravidel, cílů a zásad, raději bych se snažil co nejvíce používat laické výrazy a čmárat, abych vám poskytl nějaké informace o doméně. Mimochodem, když jsem poprvé čelil tomuto nástroji, byl jsem také docela zmatený terminologií!
Pravděpodobně už víte, že iptables má něco společného s IP pakety. Možná ještě hlubší - paketová filtrace. Nebo nejhlubší - modifikace paketů! A možná jste slyšeli, že vše se děje na straně jádra, aniž by byl zapojen kód uživatelského prostoru. Za tímto účelem poskytuje iptables speciální syntaxi pro kódování různých pravidel ovlivňujících pakety…
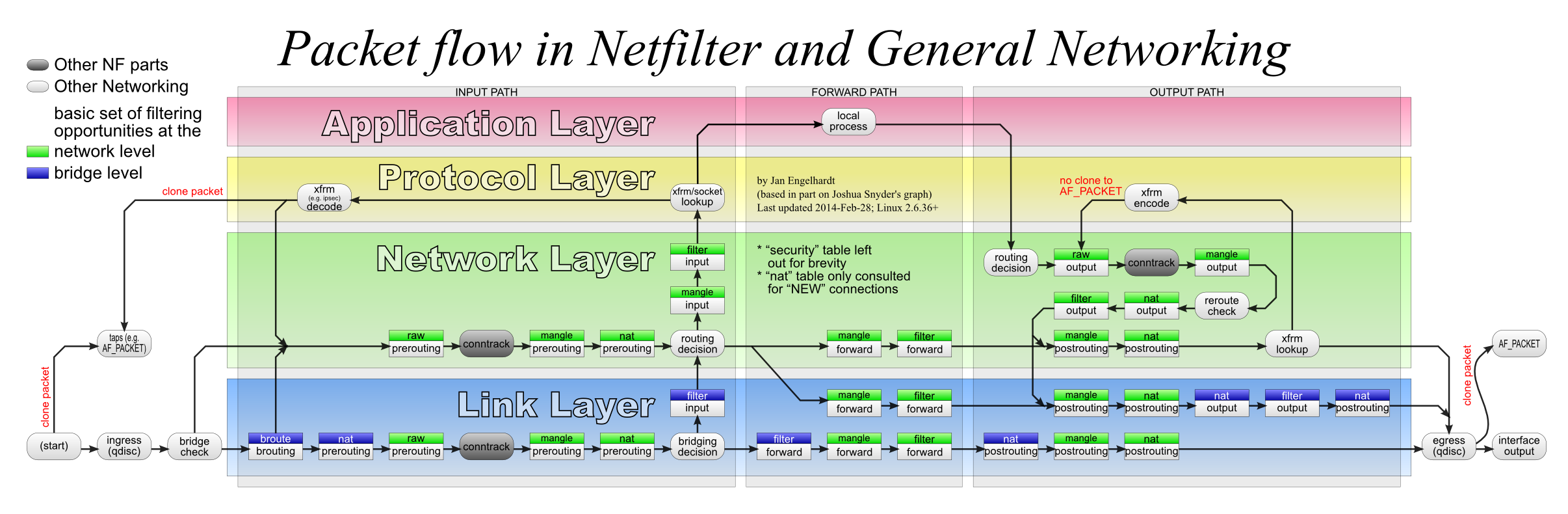
Linuxový síťový zásobník (network stack)
Než se pokusíme ovlivnit šťastný život paketů v prostoru jádra, pokusme se porozumět jejich vesmíru. Když jsou pakety vytvořeny, jaké jsou jejich cesty uvnitř jádra, jaké jsou jejich původy a cíle atd.? Podívejte se na následující scénáře:
-
Paket dorazí do síťového rozhraní, projde síťovým zásobníkem a dosáhne procesu v uživatelském prostoru.
-
Paket je vytvořen procesem uživatelského prostoru, odeslán do síťového zásobníku a poté doručen do síťového rozhraní.
-
Paket dorazí na síťové rozhraní a poté je v souladu s některými směrovacími pravidly předán na jiné síťové rozhraní.
Co je společné mezi všemi těmito scénáři? V podstatě všechny popisují cesty paketů od síťového rozhraní přes síťový zásobník až po proces v uživatelském prostoru (nebo jiné rozhraní) a obraty. Když zde říkám síťový zásobník, mám na mysli pouze spoustu vrstev poskytovaných linuxovým jádrem pro zpracování síťového přenosu a příjmu dat.
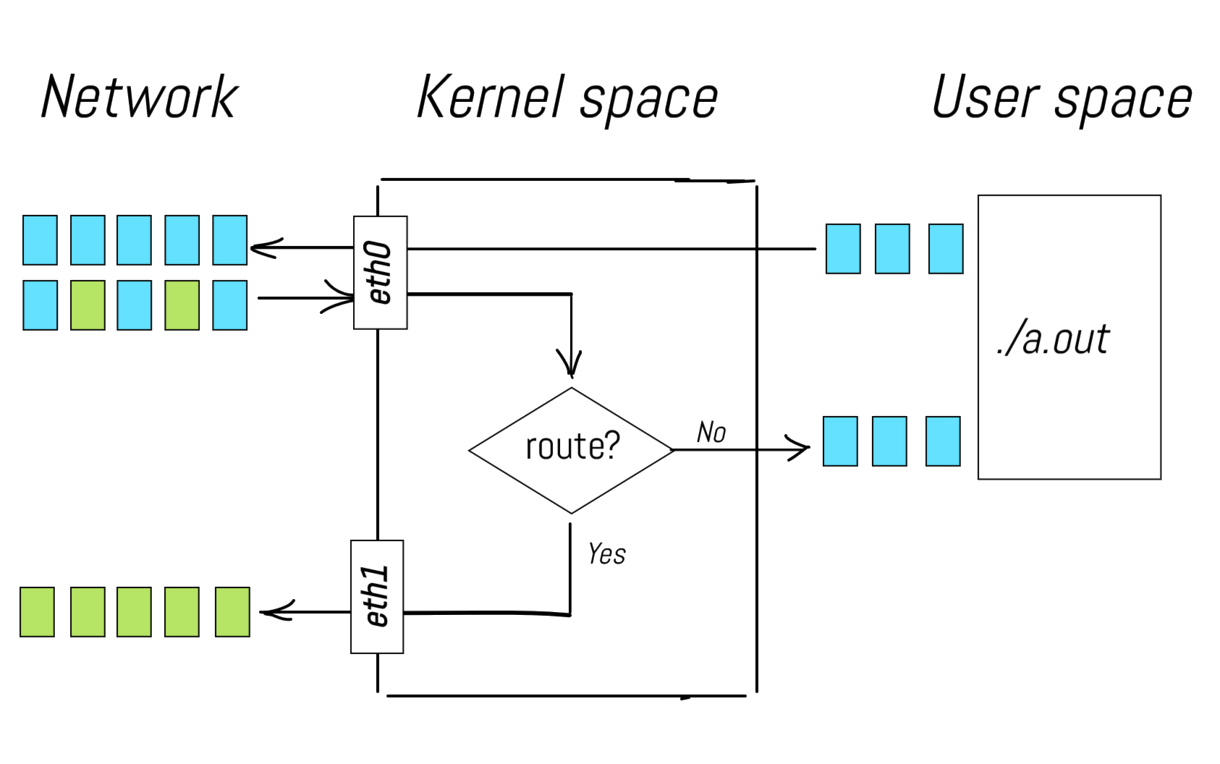
Směrovací část uprostřed zajišťuje vestavěná schopnost linuxového jádra, známá také jako IP forwarding.
Odeslání nenulové hodnoty do souboru /proc/sys/net/ipv4/ip_forward aktivuje předávání paketů mezi různými síťovými rozhraními, čímž se počítač se systémem Linux efektivně změní na směrovač.
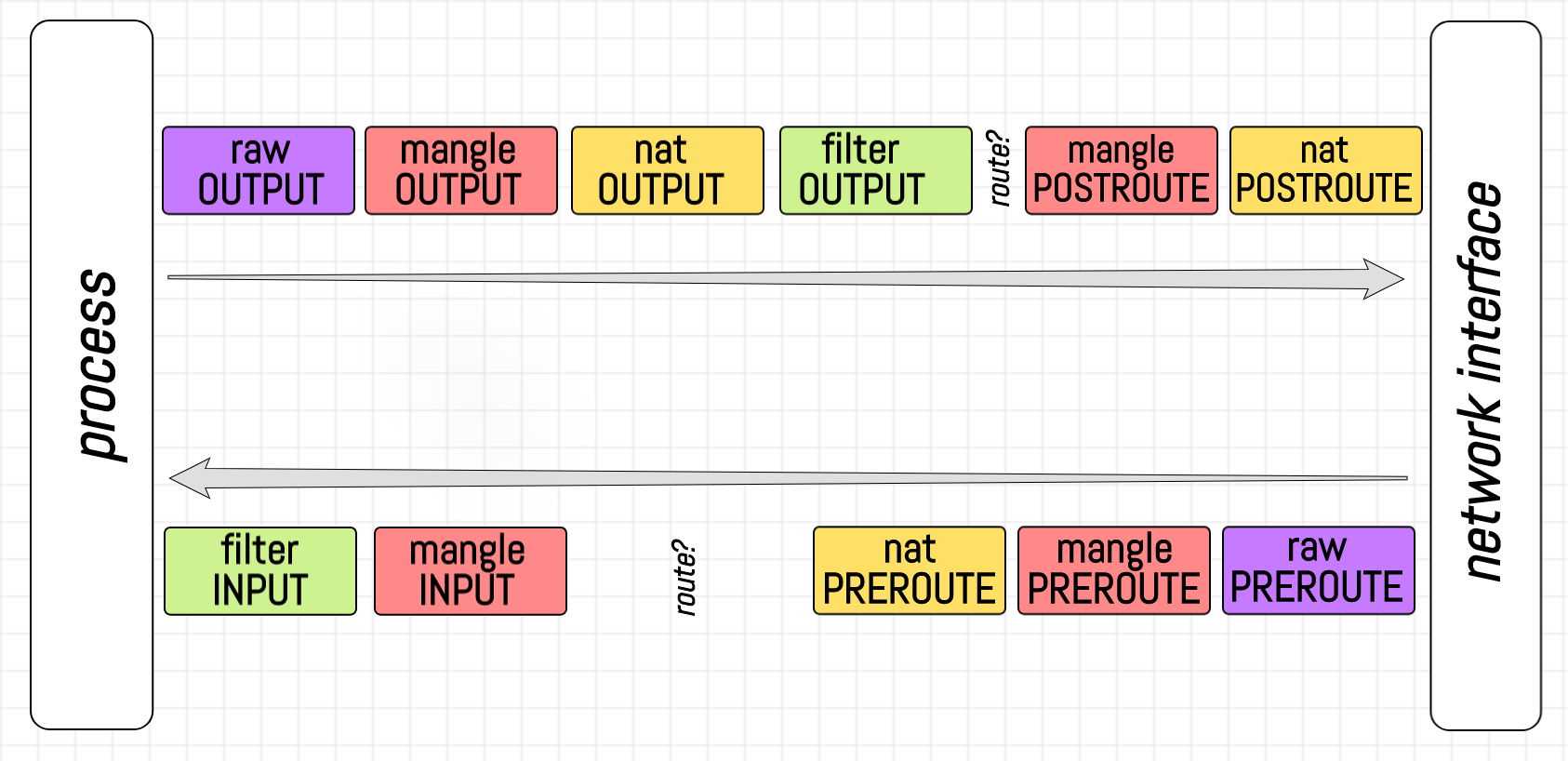
Je víceméně zřejmé, že správně navržený síťový zásobník by měl mít různé logické fáze zpracování paketů. Například fáze PREROUTING by se mohla nacházet někde mezi přijímáním paketů a skutečnou procedurou směrování. Dalším příkladem může být INPUT fáze, která se nachází bezprostředně před procesem uživatelského prostoru.
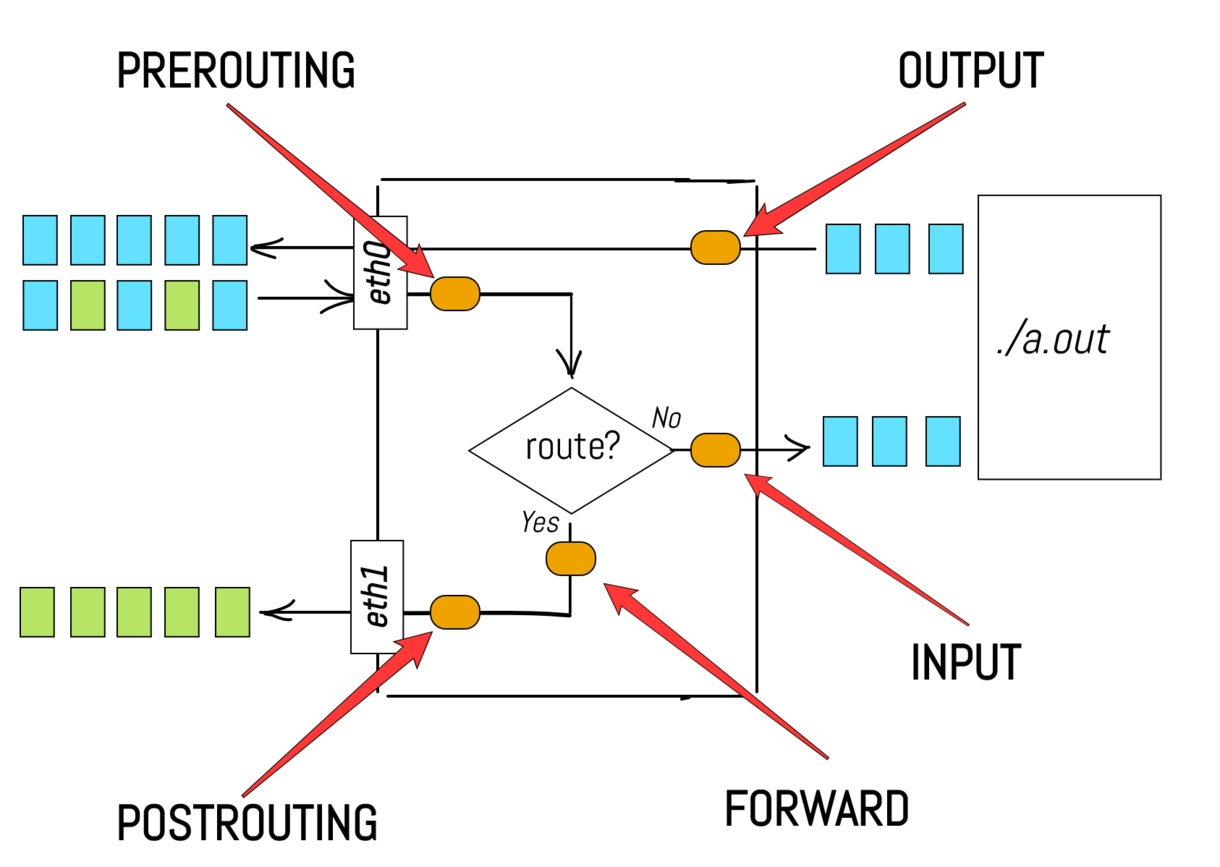
Ve skutečnosti síťový zásobník Linuxu takové logické oddělení fází poskytuje. Nyní se vraťme k našemu primárnímu úkolu – filtraci a/nebo úpravě paketů. Co když chceme zahodit nějaké pakety přicházející do procesu a.out? Například se nám nemusí líbit pakety s jednou konkrétní zdrojovou IP adresou, protože máme podezření, že tato IP patří uživateli se zlými úmysly. Bylo by skvělé mít háček v síťovém zásobníku, který by odpovídal fázi INPUT a umožňoval použití nějaké extra logiky na příchozí pakety. V našem příkladu můžeme chtít vložit funkci pro kontrolu zdrojové IP adresy paketu a na základě této informace rozhodnout, zda paket zahodit nebo přijmout.
Obecně řečeno, potřebujeme způsob, jak zaregistrovat libovolnou funkci zpětného volání, která se má provést na každém příchozím paketu v dané fázi. Naštěstí existuje projekt s názvem netfilter, který poskytuje přesně tuto funkci! Kód netfilteru se nachází uvnitř linuxového jádra a přidává všechny tyto rozšiřující body (tj. háčky) do různých fází síťového zásobníku. Je pozoruhodné, že iptables je pouze jedním z několika frontendových nástrojů uživatelského prostoru pro konfiguraci háčků netfilter. Zde je třeba ještě poznamenat - funkčnost netfilteru není omezena síťovou (tedy IP) vrstvou, možná je například i úprava ethernetových rámců. Jak však vyplývá z názvu, iptables se zaměřuje na vrstvy počínaje sítí (IP) a výše.
Uvedení do řetezců (chains) firewallu iptables
Nyní se konečně pokusme porozumět terminologii iptables. Možná jste si již všimli, že názvy, které používáme pro fáze v síťovém zásobníku, odpovídají řetězcům iptables. Ale proč by pro to proboha někdo používal slovo řetěz (chain)? Neznám za tím žádnou anekdotu, ale jeden způsob, jak vysvětlit pojmenování, je podívat se na použití:
# přidáme pravidlo "LOG every packet" do řetězce INPUT
$ iptables --append INPUT --jump LOG
# přidáme pravidlo "DROP every packet" do řetezce INPUT
$ iptables --append INPUT --jump DROPVe výše uvedeném úryvku jsme do fáze INPUT přidali několik zpětných volání, což je naprosto legitimní použití iptables. Z toho však vyplývá, že musí být definováno pořadí provádění zpětných volání. Ve skutečnosti, když dorazí nový paket, provede se nejprve první přidané zpětné volání (LOG the packet), poté se provede druhé zpětné volání (DROP paket). Všechna naše zpětná volání byla tedy seřazena do řetězce! Ale řetězec je pojmenován podle logické fáze, ve které sídlí. Zatím skončeme s řetězci a přejděme na další části iptables. Později uvidíme, že v řetězové abstrakci existuje určitá nejednoznačnost.
Pravidla (rules), cíle (targets) a politky (policies) firewallu iptables
Dále přichází pravidlo (rule). Pravidla, která jsme použili v našem příkladu výše, jsou základní. Nejprve bezpodmínečně LOGUJEME zprávu jádra pro každý paket v řetězci INPUT, poté bezpodmínečně zahodíme každý paket ze síťového zásobníku. Pravidla však mohou být složitější. Obecně pravidlo určuje kritéria pro paket a cíl. Pro zjednodušení nyní definujeme cíl (target) jako pouhou akci, jako je LOG, ACCEPT nebo DROP, a podívejme se na několik příkladů:
# blokujeme pakety se zdrojovou IP adresou 46.36.222.157
# -A je zkratka pro --append
# -j je zkrtka pro --jump
$ iptables -A INPUT -s 46.36.222.157 -j DROP
# blokujeme otchozí SSH spojení
$ iptables -A OUTPUT -p tcp --dport 22 -j DROP
# povolíme všechna příchozí HTTP(S) spojení
$ iptables -A INPUT -p tcp -m multiport --dports 80,443 -m conntrack --ctstate NEW,ESTABLISHED -j ACCEPT
$ iptables -A OUTPUT -p tcp -m multiport --dports 80,443 -m conntrack --ctstate ESTABLISHED -j ACCEPTJak vidíme, kritéria pravidla mohou být poměrně složitá. Než se rozhodneme pro akci, můžeme zkontrolovat více atributů paketu nebo dokonce některé vlastnosti TCP spojení (to znamená, že netfilter je stavový, díky modulu conntrack). Omlouvám se za to, ale programátor ve mně vyžaduje napsání nějakého kódu:
def handle_packet(packet, chain):
for rule in chain:
modules = rule.modules
for m in modules:
m.ensure_loaded()
conditions = rule.conditions
if all(c.apply(packet) for c in conditions):
# terminating target, break the chain
if rule.target in ('ACCEPT', 'DROP'):
return rule.target
# TODO: handle other targets
# TODO: what shall we do if there is no single
# terminating target in the whole chain?Myšlenka je docela jednoduchá. Postupně aplikujte všechna pravidla v řetězci, dokud nenarazíte na ukončovací cíl nebo na konec řetězce. A zde si můžeme všimnout nekryté větve v našem pseudokódu. Potřebujeme výchozí akci (tj. cíl) pro pakety, kterým se podařilo dosáhnout konce řetězce, aniž by byly mezitím odeslány do jakéhokoli ukončujícího cíle. A způsob, jak to nastavit, se nazývá politika (policy):
# zkontrolujeme implicitní politiky
$ sudo iptables --list-rules # nebo -S
-P INPUT ACCEPT
-P FORWARD ACCEPT
-P OUTPUT ACCEPT
# změníme politiku pro řetězec FORWARD na cíl DROP (zahodit)
iptables --policy FORWARD DROP # or -Piptables pokračování
Nakonec se pojďme naučit, proč se cílům říká cíle (targets), nikoli akce nebo něco jiného.
Podívejme se na příkaz, který jsme použili k nastavení pravidla iptables -A INPUT -s 46.36.222.157 -j DROP, kde -j zastupuje --jumps.
To znamená, že v důsledku pravidla můžeme skočit na cíl.
Z manuálové stránky iptables:
-j, --jump cíl skoku
Toto specifikuje cíl pravidla; tj. co dělat pokud se s ním paket shoduje.
Cíl může být uživatelsky definovaný řetězec (jiný než ten, ve kterém je toto pravidlo),
jeden z speciálních vestavěných cílů, které rozhodují o osudu paketu okamžitě, nebo zprostředkovaně (viz ROZŠÍŘENÍ níže).Tady to je! Uživatelsky definované řetězce! Jako obvykle se nejprve podívejme na příklad:
$ iptables -P INPUT ACCEPT
# implicitně zahodíme všechno předávání
$ iptables -P FORWARD DROP
$ iptables -P OUTPUT ACCEPT
# vytvoříme nový řetězec
$ iptables -N DOCKER # or --new-chain
# je-li odchozí ethernetové rozhraní docker0, skočíme do řetezce DOCKER
$ iptables -A FORWARD -o docker0 -j DOCKER
# přidáme některá pravidla, týkající se Dockeru do uživatelsky definovaného řetězce
$ iptables -A DOCKER ...
$ iptables -A DOCKER ...
$ iptables -A DOCKER ...
# skočíme zpět do volajícího řetězce (t.j. FORWARD)
$ iptables -A DOCKER -j RETURNAle jak to? Jak jsme viděli výše, řetězce měly individuální shodu s předdefinovanými logickými fázemi síťového zásobníku. Znamená skutečnost, že uživatelé mohou definovat své vlastní řetězce, že můžeme zavést nové fáze do manipulačního kanálu jádra? Sotva si to myslím. Možná se zde úplně mýlím, ale mně to připadá jako porušení zásady jednotné odpovědnosti. Řetěz se zdá být dobrou abstrakcí pro pojmenovanou sekvenci pravidel. V tradičních programovacích jazycích existuje určitá podobnost mezi řetězci a pojmenovanými podprogramy (aka funkcemi nebo procedurami). Schopnost přeskočit z libovolného místa v jednom řetězci na začátek jiného řetězce a poté se VRATIT do řetězce volajících činí podobnost ještě silnější. Řetězce PREROUTING, INPUT, FORWARD, OUTPUT a POSTROUTING však mají zvláštní význam a nelze je přepsat. Vidím určitou podobnost s funkcí main() v některých programovacích jazycích, které mají speciální účel, ale tato dvojitá povaha řetězců mi způsobila, že křivka učení iptables je pro mě docela strmá.
Abych to shrnul, uživatelsky definovaný řetězec je speciální druh cíle, který se používá jako pojmenovaná sekvence pravidel. Možnosti uživatelsky definovaných řetězců jsou dosti omezené. Uživatelsky definovaný řetězec například nemůže mít zásady. Z manuálové stránky iptables:
-P, --policy cíl řetězce zásad
Nastaví politiku (zásady) pro řetězec na daný cíl.
Podívejte se do části TARGETS, abyste viděli, jak to funguje.
Pouze vestavěné (uživatelem nedefinované) řetězce mohou mít zásady,
a ani vestavěné, ani uživatelem definované řetězce nemohou být cílem politiky.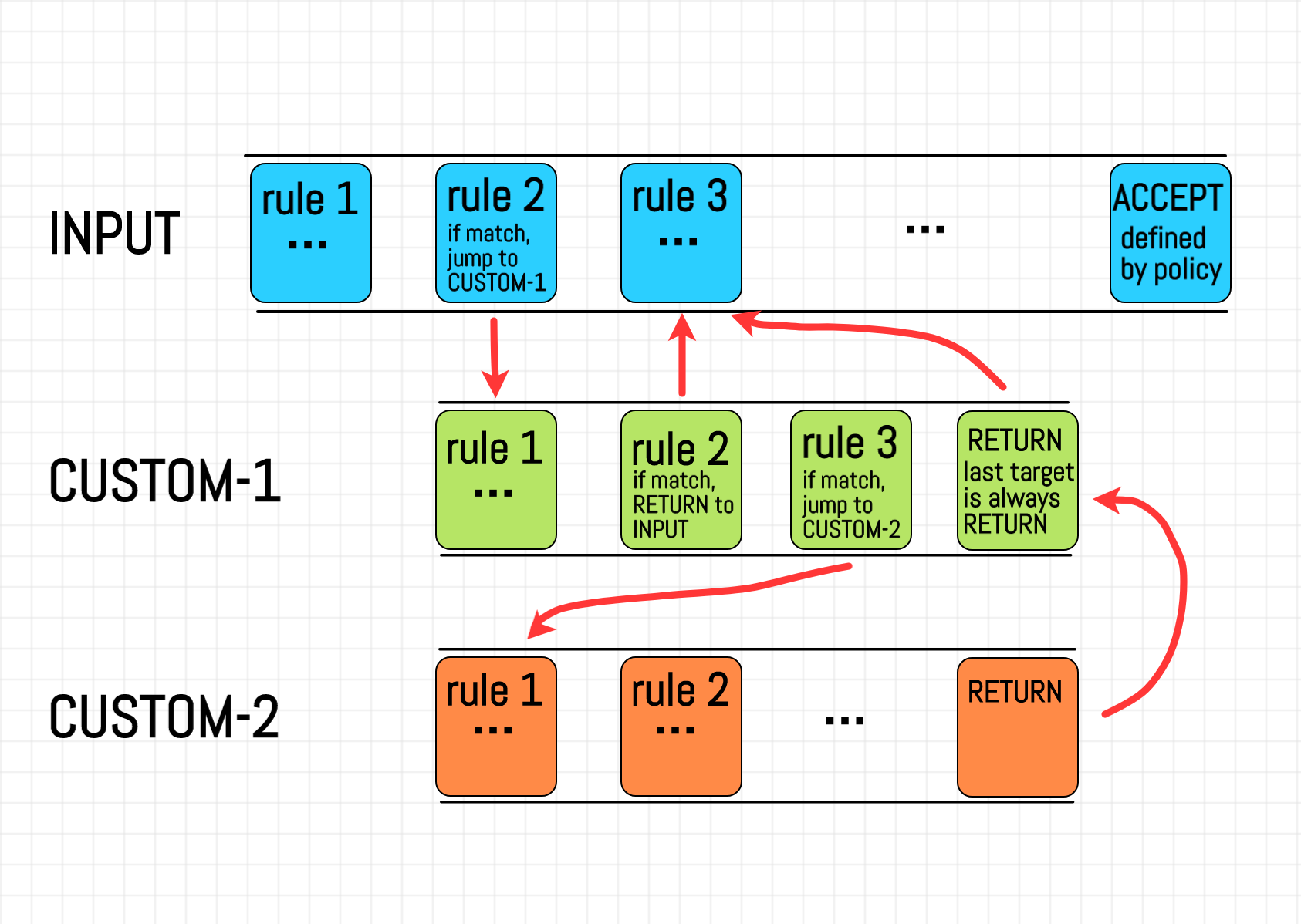
Je zřejmé, že výše uvedený úryvek kódu by měl být výrazně přepsán, aby zahrnoval manipulaci s uživatelsky definovanými řetězci.
Tabulky v iptables
No, už jsme skoro tam! Probrali jsme řetězce, pravidla a zásady. Nyní je konečně čas dozvědět se něco o tabulkách. Koneckonců, nástroj se nazývá ip*tables*.
Ve skutečnosti jsme ve všech výše uvedených příkladech implicitně použili tabulku zvanou filter. Nejsem si jistý oficiální definicí tabulky, ale vždy označuji tabulku jako logické seskupení a izolaci řetězců. Jak již víme, existuje tabulka pro řetězce, které spravují filtraci paketů. Pokud však chceme některé pakety upravit, existuje další tabulka, nazvaná mangle/. Je to absolutně oprávněné přání mít možnost filtrovat pakety na fázi *FORWARD. Je však také v pořádku upravit pakety na této fázi. Filtrační i mangle tabulky tedy budou mít řetězy FORWARD. Tyto řetězce jsou však zcela nezávislé.
Počet podporovaných tabulek se může mezi různými verzemi jádra lišit, ale nejvýraznější tabulky jsou obvykle zde:
filter:
Toto je výchozí tabulka (pokud není předána volba -t). Obsahuje
vestavěné řetězce INPUT (pro pakety určené do místních soketů),
FORWARD (pro pakety směrované přes box) a OUTPUT
(pro lokálně generované pakety).nat:
Tato tabulka je konzultována, když je zjištěn paket, který vytváří nové připojení.
Skládá se ze tří vestavěných funkcí: PREROUTING (pro změnu paketů, jakmile
přicházejí), OUTPUT (pro změnu lokálně generovaných paketů před směrováním),
a POSTROUTING (pro změnu paketů, když se chystají odejít). Podpora IPv6 NAT
je k dispozici od jádra 3.7.mangle:
Tato tabulka se používá pro specializované změny paketů. Do jádra 2.4.17 měl dva
vestavěné řetězce: PREROUTING (pro změnu příchozích paketů před směrováním)
a OUTPUT (pro změnu lokálně generovaných paketů před směrováním). Od jádra 2.4.18
Podporovány jsou také tři další vestavěné řetězce: INPUT (pro pakety přicházející do schránky
sám), FORWARD (pro změnu paketů směrovaných přes box) a POSTROUTING
(pro změnu paketů, když se chystají odejít).raw:
Tato tabulka se používá hlavně pro konfiguraci výjimek ze sledování připojení
kombinaci s terčem NOTRACK. Registruje se na háčky netfilter s
vyšší prioritu a je tedy volán před ip_conntrack nebo jinými IP tabulkami.
Poskytuje následující vestavěné řetězce: PREROUTING (pro pakety přicházející přes
libovolné síťové rozhraní) VÝSTUP (pro pakety generované místními procesy)security:
Tato tabulka se používá pro síťová pravidla povinného řízení přístupu (MAC), jako jsou tato
povoleno cíli SECMARK a CONNSECMARK. Je implementována povinná kontrola přístupu
pomocí bezpečnostních modulů Linuxu, jako je SELinux. Tabulka zabezpečení se volá po filtru
tabulky, což umožňuje převzít všechna pravidla řízení přístupu (DAC) v tabulce filtrů
účinek před pravidly MAC. Tato tabulka obsahuje následující vestavěné řetězce: INPUT (pro
pakety přicházející do samotné schránky), OUTPUT (pro změnu lokálně generovaných paketů dříve
routing) a FORWARD (pro změnu paketů směrovaných přes box).Co je zde opravdu zajímavé, je kolize řetězců mezi tabulkami. Co se stane s paketem, pokud má řetězec filter.INPUT cíl DROP, ale řetězec mangle.INPUT má cíl ACCEPT, obojí v rámci potvrzujících pravidel? Který řetězec má vyšší prioritu? Zkusme to zkontrolovat!
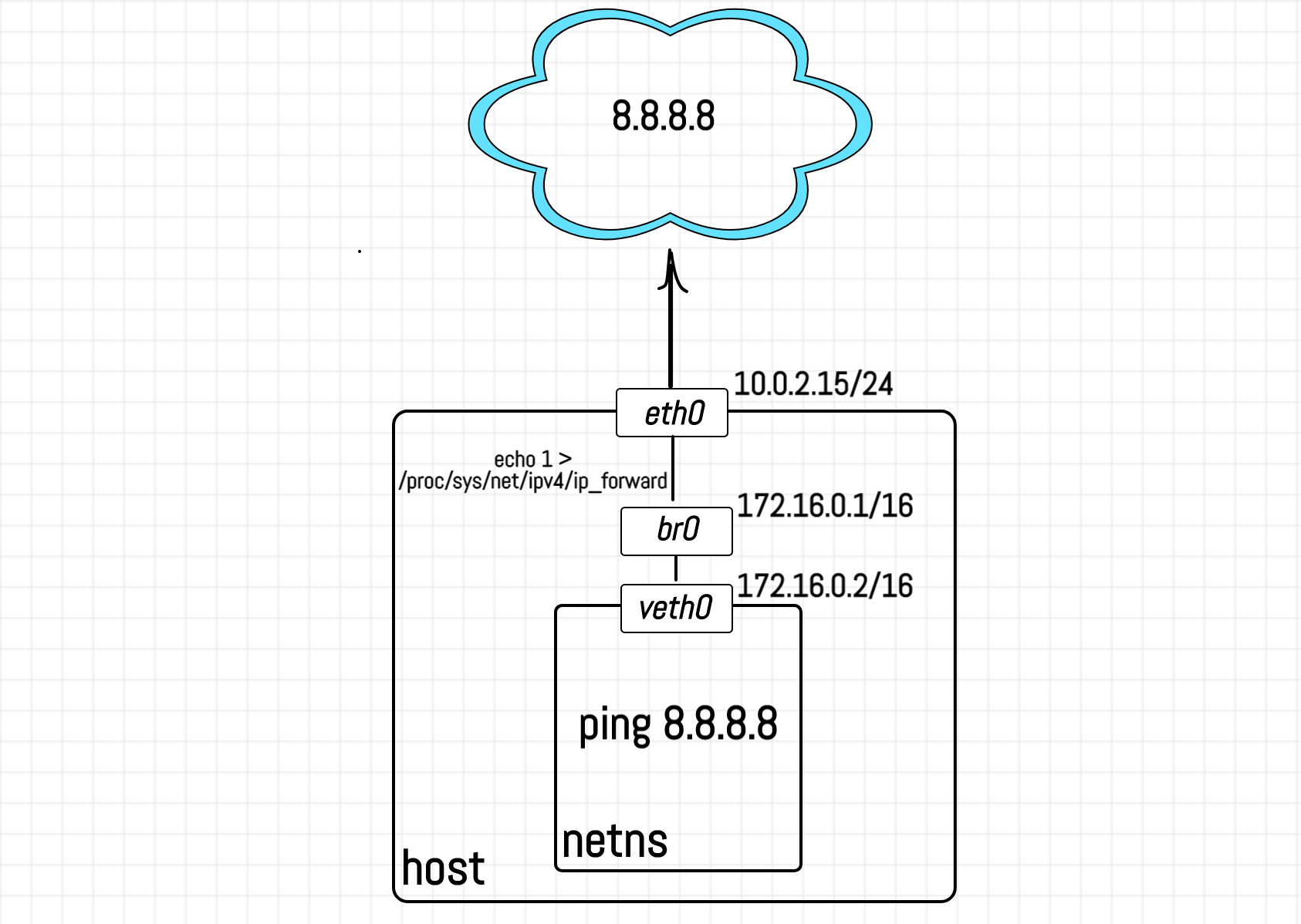
Nastavení pokusu
Potřebujeme logy pro síťové zásobníky klienta i routeru ve stejném streamu, abychom měli komplexní přehled o vztazích mezi tabulkami a řetězci.
Za tímto účelem budeme simulovat 2 stroje na jednom hostiteli Linuxu pomocí funkce síťových jmenných prostorů.
Hlavní částí experimentu je protokolování IP paketů.
Cíl LOG byl na dlouhou dobu deaktivován pro jmenné prostory jiného typu než root, aby se zabránilo potenciálnímu odmítnutí služby hostitelem z izolovaných procesů.
Naštěstí od linuxového jádra 4.11 existuje způsob, jak povolit protokoly netfilter pro jmenné prostory odesláním nenulové hodnoty do /proc/sys/net/netfilter/nf_log_all_netns.
Ale nedělejte to na ostrém serveru!
Nejprve vytvořte síťový jmenný prostor:
# spustíme přímo na železe (na hostiteli):
$ unshare -r --net bash
# namespace (same terminal session):
$ echo $$
2979 # zapamatujeme si toto PIDV druhém terminálu, musíme si nakonfigurovat hostitele:
# run on host:
$ sudo -i
# create a veth interface
$ ip link add vGUEST type veth peer name vHOST
# move one of its peers to network namespace
$ ip link set vGUEST netns 2979 # PID from above
# create linux bridge
$ ip link add br0 type bridge
# wire vHOST to br0
$ ip link set vHOST master br0
# set IP addresses and bring devices up
$ ip addr add 172.16.0.1/16 dev br0
$ ip link set br0 up
$ ip link set vHOST up
$ ip addr
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
inet6 ::1/128 scope host
valid_lft forever preferred_lft forever
2: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP group default qlen 1000
link/ether 52:54:00:26:10:60 brd ff:ff:ff:ff:ff:ff
inet 10.0.2.15/24 brd 10.0.2.255 scope global noprefixroute dynamic eth0
valid_lft 85752sec preferred_lft 85752sec
inet6 fe80::5054:ff:fe26:1060/64 scope link
valid_lft forever preferred_lft forever
3: vHOST@if4: <NO-CARRIER,BROADCAST,MULTICAST,UP> mtu 1500 qdisc noqueue master br0 state LOWERLAYERDOWN group default qlen 1000
link/ether c2:96:cf:97:f4:12 brd ff:ff:ff:ff:ff:ff link-netnsid 0
5: br0: <NO-CARRIER,BROADCAST,MULTICAST,UP> mtu 1500 qdisc noqueue state DOWN group default qlen 1000
link/ether c2:96:cf:97:f4:12 brd ff:ff:ff:ff:ff:ff
inet 172.16.0.1/16 scope global br0
valid_lft forever preferred_lft forever
# turn the host into a virtual router
iptables -t nat -A POSTROUTING -o eth0 -j MASQUERADE
$ echo 1 > /proc/sys/net/ipv4/ip_forward
# and don't forget to enable netfilter logs in namespaces
$ echo 1 > /proc/sys/net/netfilter/nf_log_all_netnsNyní dokončíme nastavení síťového rozhraní na straně jmenného prostoru:
# run in network namespace:
# bring devices up
$ ip link set lo up
$ ip link set vGUEST up
# configure IP address
$ ip addr add 172.16.0.2/16 dev vGUEST
$ ip addr
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
inet6 ::1/128 scope host
valid_lft forever preferred_lft forever
4: vGUEST@if3: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP group default qlen 1000
link/ether c2:31:a8:8b:d7:f8 brd ff:ff:ff:ff:ff:ff link-netnsid 0
inet 172.16.0.2/16 scope global vGUEST
valid_lft forever preferred_lft forever
inet6 fe80::c031:a8ff:fe8b:d7f8/64 scope link
valid_lft forever preferred_lft forever
# set default route via br0
$ ip route add default via 172.16.0.1
$ ip route
default via 172.16.0.1 dev vGUEST
172.16.0.0/16 dev vGUEST proto kernel scope link src 172.16.0.2Zkontrolujeme a aktualizujeme pravidla iptables ve jmenném prostoru:
# run in network namespace:
$ iptables -S -t filter
-P INPUT ACCEPT
-P FORWARD ACCEPT
-P OUTPUT ACCEPT
$ iptables -S -t nat
-P PREROUTING ACCEPT
-P INPUT ACCEPT
-P OUTPUT ACCEPT
-P POSTROUTING ACCEPT
$ iptables -S -t mangle
-P PREROUTING ACCEPT
-P INPUT ACCEPT
-P FORWARD ACCEPT
-P OUTPUT ACCEPT
-P POSTROUTING ACCEPT
$ iptables -S -t raw
-P PREROUTING ACCEPT
-P OUTPUT ACCEPT
$ iptables -t filter -A INPUT -j LOG --log-prefix "NETNS_FILTER_INPUT "
$ iptables -t filter -A FORWARD -j LOG --log-prefix "NETNS_FILTER_FORWARD "
$ iptables -t filter -A OUTPUT -j LOG --log-prefix "NETNS_FILTER_OUTPUT "
$ iptables -t nat -A PREROUTING -j LOG --log-prefix "NETNS_NAT_PREROUTE "
$ iptables -t nat -A INPUT -j LOG --log-prefix "NETNS_NAT_INPUT "
$ iptables -t nat -A OUTPUT -j LOG --log-prefix "NETNS_NAT_OUTPUT "
$ iptables -t nat -A POSTROUTING -j LOG --log-prefix "NETNS_NAT_POSTROUTE "
$ iptables -t mangle -A PREROUTING -j LOG --log-prefix "NETNS_MANGLE_PREROUTE "
$ iptables -t mangle -A INPUT -j LOG --log-prefix "NETNS_MANGLE_INPUT "
$ iptables -t mangle -A FORWARD -j LOG --log-prefix "NETNS_MANGLE_FORWARD "
$ iptables -t mangle -A OUTPUT -j LOG --log-prefix "NETNS_MANGLE_OUTPUT "
$ iptables -t mangle -A POSTROUTING -j LOG --log-prefix "NETNS_MANGLE_POSTROUTE "
$ iptables -t raw -A PREROUTING -j LOG --log-prefix "NETNS_RAW_PREROUTE "
$ iptables -t raw -A OUTPUT -j LOG --log-prefix "NETNS_RAW_OUTPUT "Všimněte si, že pravidla iptables na hostiteli nejsou ovlivněna nastavením z oboru názvů:
# run on host:
$ iptables -S -t filter
-P INPUT ACCEPT
-P FORWARD ACCEPT
-P OUTPUT ACCEPT
$ iptables -S -t nat
-P PREROUTING ACCEPT
-P INPUT ACCEPT
-P OUTPUT ACCEPT
-P POSTROUTING ACCEPT
-A POSTROUTING -o eth0 -j MASQUERADE
$ iptables -S -t mangle
-P PREROUTING ACCEPT
-P INPUT ACCEPT
-P FORWARD ACCEPT
-P OUTPUT ACCEPT
-P POSTROUTING ACCEPT
$ iptables -S -t raw
-P PREROUTING ACCEPT
-P OUTPUT ACCEPTAktualizujeme pravidla iptables na hostiteli:
# run on host:
$ iptables -t filter -A INPUT -j LOG --log-prefix "HOST_FILTER_INPUT "
$ iptables -t filter -A FORWARD -j LOG --log-prefix "HOST_FILTER_FORWARD "
$ iptables -t filter -A OUTPUT -j LOG --log-prefix "HOST_FILTER_OUTPUT "
$ iptables -t nat -A PREROUTING -j LOG --log-prefix "HOST_NAT_PREROUTE "
$ iptables -t nat -A INPUT -j LOG --log-prefix "HOST_NAT_INPUT "
$ iptables -t nat -A OUTPUT -j LOG --log-prefix "HOST_NAT_OUTPUT "
$ iptables -t nat -A POSTROUTING -j LOG --log-prefix "HOST_NAT_POSTROUTE "
$ iptables -t mangle -A PREROUTING -j LOG --log-prefix "HOST_MANGLE_PREROUTE "
$ iptables -t mangle -A INPUT -j LOG --log-prefix "HOST_MANGLE_INPUT "
$ iptables -t mangle -A FORWARD -j LOG --log-prefix "HOST_MANGLE_FORWARD "
$ iptables -t mangle -A OUTPUT -j LOG --log-prefix "HOST_MANGLE_OUTPUT "
$ iptables -t mangle -A POSTROUTING -j LOG --log-prefix "HOST_MANGLE_POSTROUTE "
$ iptables -t raw -A PREROUTING -j LOG --log-prefix "HOST_RAW_PREROUTE "
$ iptables -t raw -A OUTPUT -j LOG --log-prefix "HOST_RAW_OUTPUT "A nakonec ping 8.8.8.8 z oboru názvů při úpravě zpráv jádra na hostiteli:
# run in network namespace:
$ ping 8.8.8.8# run on host:
$ tail -f /var/log/messagesK tomu musíme přidat cíle LOG do všech řetězců všech tabulek a provést následující experiment:
Nyní, když začneme pingovat externí adresu, jako je 8.8.8.8, můžeme si všimnout zajímavého vzoru vznikajícího v protokolech netfilter:
Jun 21 13:25:19 localhost kernel: NETNS_RAW_OUTPUT IN= OUT=vGUEST SRC=172.16.0.2 DST=8.8.8.8 LEN=84 TOS=0x00 PREC=0x00 TTL=64 ID=2089 DF PROTO=ICMP TYPE=8 CODE=0 ID=3197 SEQ=34
Jun 21 13:25:19 localhost kernel: NETNS_MANGLE_OUTPUT IN= OUT=vGUEST SRC=172.16.0.2 DST=8.8.8.8 LEN=84 TOS=0x00 PREC=0x00 TTL=64 ID=2089 DF PROTO=ICMP TYPE=8 CODE=0 ID=3197 SEQ=34
Jun 21 13:25:19 localhost kernel: NETNS_FILTER_OUTPUT IN= OUT=vGUEST SRC=172.16.0.2 DST=8.8.8.8 LEN=84 TOS=0x00 PREC=0x00 TTL=64 ID=2089 DF PROTO=ICMP TYPE=8 CODE=0 ID=3197 SEQ=34
Jun 21 13:25:19 localhost kernel: NETNS_MANGLE_POSTROUTE IN= OUT=vGUEST SRC=172.16.0.2 DST=8.8.8.8 LEN=84 TOS=0x00 PREC=0x00 TTL=64 ID=2089 DF PROTO=ICMP TYPE=8 CODE=0 ID=3197 SEQ=34
Jun 21 13:25:19 localhost kernel: HOST_RAW_PREROUTE IN=br0 OUT= MAC=c2:96:cf:97:f4:12:c2:31:a8:8b:d7:f8:08:00 SRC=172.16.0.2 DST=8.8.8.8 LEN=84 TOS=0x00 PREC=0x00 TTL=64 ID=2089 DF PROTO=ICMP TYPE=8 CODE=0 ID=3197 SEQ=34
Jun 21 13:25:19 localhost kernel: HOST_MANGLE_PREROUTE IN=br0 OUT= MAC=c2:96:cf:97:f4:12:c2:31:a8:8b:d7:f8:08:00 SRC=172.16.0.2 DST=8.8.8.8 LEN=84 TOS=0x00 PREC=0x00 TTL=64 ID=2089 DF PROTO=ICMP TYPE=8 CODE=0 ID=3197 SEQ=34
Jun 21 13:25:19 localhost kernel: HOST_MANGLE_FORWARD IN=br0 OUT=eth0 MAC=c2:96:cf:97:f4:12:c2:31:a8:8b:d7:f8:08:00 SRC=172.16.0.2 DST=8.8.8.8 LEN=84 TOS=0x00 PREC=0x00 TTL=63 ID=2089 DF PROTO=ICMP TYPE=8 CODE=0 ID=3197 SEQ=34
Jun 21 13:25:19 localhost kernel: HOST_FILTER_FORWARD IN=br0 OUT=eth0 MAC=c2:96:cf:97:f4:12:c2:31:a8:8b:d7:f8:08:00 SRC=172.16.0.2 DST=8.8.8.8 LEN=84 TOS=0x00 PREC=0x00 TTL=63 ID=2089 DF PROTO=ICMP TYPE=8 CODE=0 ID=3197 SEQ=34
Jun 21 13:25:19 localhost kernel: HOST_MANGLE_POSTROUTE IN= OUT=eth0 SRC=172.16.0.2 DST=8.8.8.8 LEN=84 TOS=0x00 PREC=0x00 TTL=63 ID=2089 DF PROTO=ICMP TYPE=8 CODE=0 ID=3197 SEQ=34
Jun 21 13:25:19 localhost kernel: HOST_RAW_PREROUTE IN=eth0 OUT= MAC=52:54:00:26:10:60:52:54:00:12:35:02:08:00 SRC=8.8.8.8 DST=10.0.2.15 LEN=84 TOS=0x00 PREC=0x00 TTL=62 ID=17376 DF PROTO=ICMP TYPE=0 CODE=0 ID=3197 SEQ=34
Jun 21 13:25:19 localhost kernel: HOST_MANGLE_PREROUTE IN=eth0 OUT= MAC=52:54:00:26:10:60:52:54:00:12:35:02:08:00 SRC=8.8.8.8 DST=10.0.2.15 LEN=84 TOS=0x00 PREC=0x00 TTL=62 ID=17376 DF PROTO=ICMP TYPE=0 CODE=0 ID=3197 SEQ=34
Jun 21 13:25:19 localhost kernel: HOST_MANGLE_FORWARD IN=eth0 OUT=br0 MAC=52:54:00:26:10:60:52:54:00:12:35:02:08:00 SRC=8.8.8.8 DST=172.16.0.2 LEN=84 TOS=0x00 PREC=0x00 TTL=61 ID=17376 DF PROTO=ICMP TYPE=0 CODE=0 ID=3197 SEQ=34
Jun 21 13:25:19 localhost kernel: HOST_FILTER_FORWARD IN=eth0 OUT=br0 MAC=52:54:00:26:10:60:52:54:00:12:35:02:08:00 SRC=8.8.8.8 DST=172.16.0.2 LEN=84 TOS=0x00 PREC=0x00 TTL=61 ID=17376 DF PROTO=ICMP TYPE=0 CODE=0 ID=3197 SEQ=34
Jun 21 13:25:19 localhost kernel: HOST_MANGLE_POSTROUTE IN= OUT=br0 SRC=8.8.8.8 DST=172.16.0.2 LEN=84 TOS=0x00 PREC=0x00 TTL=61 ID=17376 DF PROTO=ICMP TYPE=0 CODE=0 ID=3197 SEQ=34
Jun 21 13:25:19 localhost kernel: NETNS_RAW_PREROUTE IN=vGUEST OUT= MAC=c2:31:a8:8b:d7:f8:c2:96:cf:97:f4:12:08:00 SRC=8.8.8.8 DST=172.16.0.2 LEN=84 TOS=0x00 PREC=0x00 TTL=61 ID=17376 DF PROTO=ICMP TYPE=0 CODE=0 ID=3197 SEQ=34
Jun 21 13:25:19 localhost kernel: NETNS_MANGLE_PREROUTE IN=vGUEST OUT= MAC=c2:31:a8:8b:d7:f8:c2:96:cf:97:f4:12:08:00 SRC=8.8.8.8 DST=172.16.0.2 LEN=84 TOS=0x00 PREC=0x00 TTL=61 ID=17376 DF PROTO=ICMP TYPE=0 CODE=0 ID=3197 SEQ=34
Jun 21 13:25:19 localhost kernel: NETNS_MANGLE_INPUT IN=vGUEST OUT= MAC=c2:31:a8:8b:d7:f8:c2:96:cf:97:f4:12:08:00 SRC=8.8.8.8 DST=172.16.0.2 LEN=84 TOS=0x00 PREC=0x00 TTL=61 ID=17376 DF PROTO=ICMP TYPE=0 CODE=0 ID=3197 SEQ=34
Jun 21 13:25:19 localhost kernel: NETNS_FILTER_INPUT IN=vGUEST OUT= MAC=c2:31:a8:8b:d7:f8:c2:96:cf:97:f4:12:08:00 SRC=8.8.8.8 DST=172.16.0.2 LEN=84 TOS=0x00 PREC=0x00 TTL=61 ID=17376 DF PROTO=ICMP TYPE=0 CODE=0 ID=3197 SEQ=34Protokoly jsou dost podrobné, ale zkuste se zaměřit pouze na předpony protokolů. Vzor je následující:
NETNS_RAW_OUTPUT
NETNS_MANGLE_OUTPUT
NETNS_FILTER_OUTPUT
NETNS_MANGLE_POSTROUTE
HOST_RAW_PREROUTE
HOST_MANGLE_PREROUTE
HOST_MANGLE_FORWARD
HOST_FILTER_FORWARD
HOST_MANGLE_POSTROUTE
HOST_RAW_PREROUTE
HOST_MANGLE_PREROUTE
HOST_MANGLE_FORWARD
HOST_FILTER_FORWARD
HOST_MANGLE_POSTROUTE
NETNS_RAW_PREROUTE
NETNS_MANGLE_PREROUTE
NETNS_MANGLE_INPUT
NETNS_FILTER_INPUTZ toho si můžeme udělat přibližnou představu o přednosti řetězců. Všimněte si, že zatímco jmenný prostor v našem příkladu se chová jako běžný klientský počítač odesílající požadavky do Internetu svou výchozí cestou, hostitel slouží jako router:
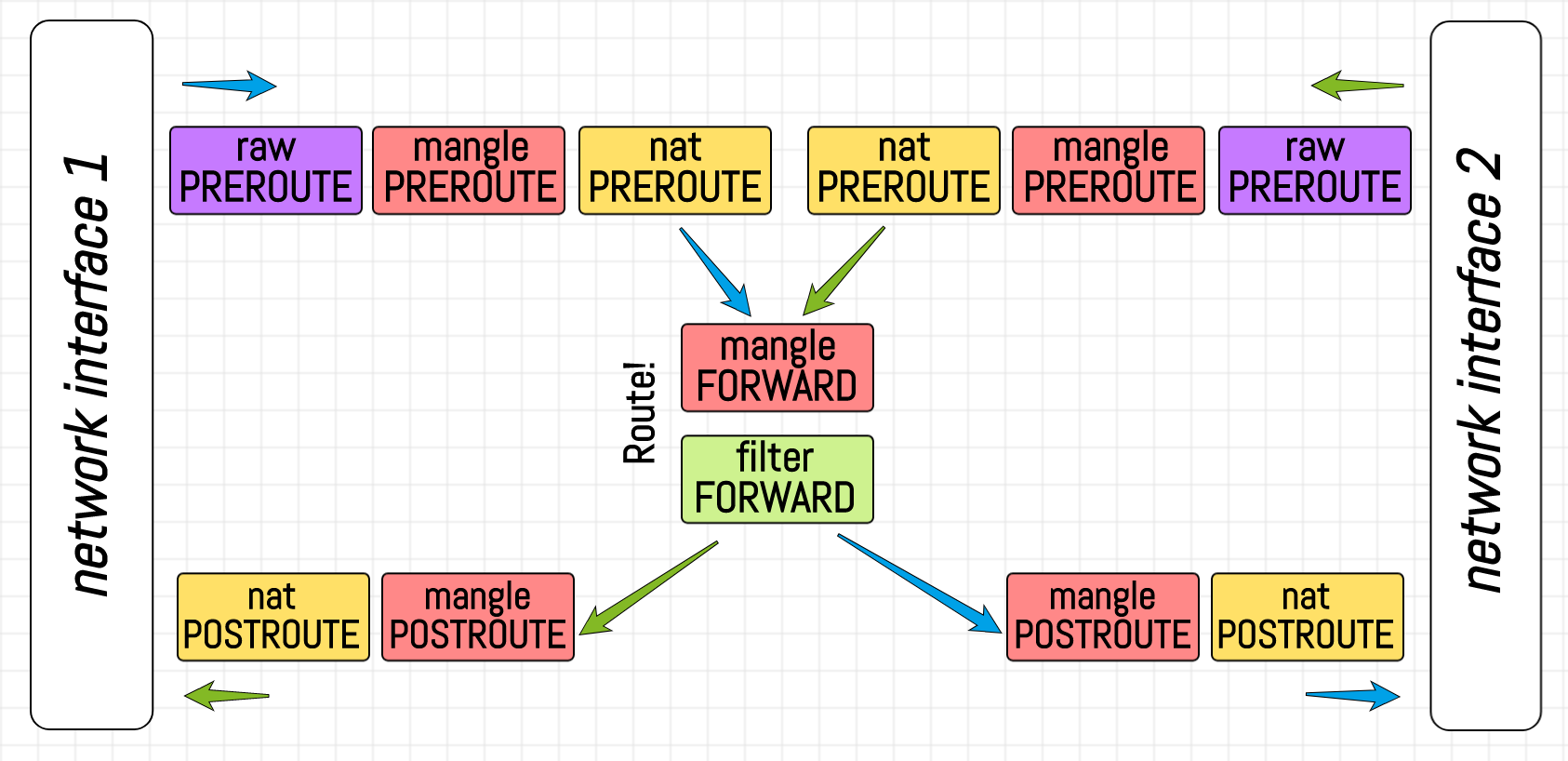
Závěr
Mohlo by to vypadat, že iptables je prastará technologie. Má smysl trávit čas učením? Ale podívejte se na Docker nebo Kubernetes – vzkvétající produkty. Oba intenzivně využívají iptables pod kapotou k nastavení a správě svých síťových vrstev! Nenechte se zmást, bez naučení se základních věcí, jako je netfilter, iptables, IPVS, nebude nikdy možné vyvinout ani provozovat moderní nástroje pro správu clusteru ve vážném měřítku.