Rychle se tenčící adresní prostor byl jedním z hlavních hnacích motorů vzniku IPv6. Přestože navržený protokol má i řadu jiných zajímavých vlastností, dodnes je košatost jeho adresního prostoru považována za klíčovou přednost a s krátící se zásobou IPv4 adres nabývá na naléhavosti. Podívejme se na ni podrobněji.
Základním dokumentem pro definici adres je RFC 4291: IP Version 6 Addressing Architecture určující jejich délku a podobu, typy adres a další koncepční prvky. Je doplněn několika dalšími dokumenty popisujícími podrobněji vybrané části adresního prostoru.
Jak se adresuje
V IPv6 – stejně jako u jeho předchůdce – jsou adresy přiřazovány síťovým rozhraním, nikoli zařízením. Má-li váš počítač dvě síťové karty, bude mít každá z nich svou adresu. Přesněji řečeno své adresy. Později uvidíte, že IPv6 s adresami pro rozhraní nikterak neskrblí. Existují tři druhy adres s odlišným chováním:
-
Individuální (unicast) jsou staré známé krotké adresy. Každá z nich identifikuje jedno síťové rozhraní a data mají být dopravena právě jemu.
-
Skupinové (multicast) slouží pro adresování skupin počítačů či jiných zařízení. Pokud někdo odešle data na tuto adresu, musí být doručena všem členům skupiny.
-
Výběrové (anycast) představují novinku a nejzajímavější přírůstek v IPv6. Také výběrové adresy označují skupinu, data se však doručí jen jedinému jejímu členovi – tomu, který je nejblíže.
Porovnání s IPv4 ukazuje, že zmizely všesměrové (broadcast) adresy. Nejsou potřeba, protože jejich funkce přebírají obecnější adresy skupinové. Jsou definovány speciální skupiny, např. pro všechny uzly na dané lince, které umožňují plošnou distribuci zpráv.
IPv6 umožňuje, aby rozhraní mělo libovolný počet adres různých druhů. Ba dokonce přikazuje několik povinných adres, které musí být přiděleny. Stejně jako v IPv4 se předpokládá, že všechny počítače v jedné fyzické síti (např. na jednom Ethernetu) budou náležet do stejné podsítě a budou tudíž mít společný prefix podsítě.
Podoba a zápis adresy
Při rozhodování o velikosti adresy pro IPv6 se autoři řídili heslem „aby nám už nikdy nedošly“. Frustrace způsobená nedostatkem IPv4 adres byla velmi silná. Proto se rozhodli délku prodloužit na čtyřnásobek, adresa v IPv6 tedy měří 128 bitů.
Standardním způsobem jejího zápisu je osm skupin po čtyřech číslicích šestnáctkové soustavy, které vyjadřují hodnoty 16 bitů dlouhých částí adresy. Navzájem se oddělují dvojtečkami. Příkladem IPv6 adresy je:
fedc:ba98:7654:3210:fedc:ba98:7654:3210
Upřímně řečeno se očekává, že uživatelé budou striktně používat DNS a ručního psaní uvedených hrůz budou ušetřeni. Černý Petr zbude v rukou správců sítí, kteří se jim při sebevětším úsilí nevyhnou…
Jelikož je poměrně častou hodnotou nula, nabízí se dvě možnosti pro zkrácení zápisu. Jednak v každé čtveřici můžete vynechat počáteční nuly. Místo „0000“ tedy lze psát jen „0“. Někdy se dokonce vyskytuje několik nulových skupin za sebou. Ty můžete nahradit zápisem „::“ (dvě dvojtečky). Například adresu:
0123:0000:0000:0000:fedc:ba98:7654:3210
můžete zkrátit na:
123:0:0:0:fedc:ba98:7654:3210
nebo dokonce jen na:
123::fedc:ba98:7654:3210
Koncovou nulu (v poslední čtveřici) pochopitelně vynechat nelze. Kdybyste napsali jen „321“, znamenalo by to „0321“, nikoli „3210“. Úplný extrém představuje nedefinovaná adresa:
0000:0000:0000:0000:0000:0000:0000:0000
kterou lze zkrátit až na samotné:
::
Konstrukci „::“ můžete v každé adrese použít jen jednou. Jinak by nebylo jednoznačné, jak se má adresa rozvinout do původní podoby. Například adresu:
123:0000:0000:0000:4567:0000:0000:0000
můžete psát jako:
123::4567:0:0:0 nebo 123:0:0:0:4567::
nikoli však:
123::4567::
Velká variabilita v zápisu adres komplikuje jejich porovnávání. Výše vidíte několik příkladů výrazně odlišných zápisů stejné adresy, navíc mohou situaci ještě komplikovat malá/velká písmena a pro lidského čtenáře v některých písmech potenciálně zaměnitelné znaky „B“ a „8“ či „D“ a „0“.
RFC 5952: A Recommendation for IPv6 Address Text Representation proto definovalo kanonický zápis, jehož cílem je učinit psanou podobu adresy jednoznačnou. Dokument zdůrazňuje, že aplikace musí podporovat všechny přípustné podoby adresy, ale ve svých výstupech, jako jsou výpisy či hodnoty v konfiguračních dialozích, by měly používat kanonický tvar. Pravidla pro jeho vytvoření jsou následující:
-
Šestnáctkové číslice reprezentované písmeny se píší vždy malými znaky.
-
Vynechání počátečních nul ve čtveřici je povinné.
-
Konstrukce „::“ musí být použita tak, aby měla největší možný efekt. Musí pohltit všechny vzájemně sousedící nulové skupiny (není povoleno „:0::“ ani „::0:“) a musí být použita pro nejdelší sekvenci nulových skupin v adrese. Má-li shodnou maximální délku několik skupin, použije se „::“ pro první z nich. Není povoleno ji použít pro jedinou nulovou skupinu, ta vždy zůstane jako jednoduchá nula.
Kanonický tvar výše uvedené adresy je 123::4567:0:0:0 a software by ji vždy měl vypisovat v této podobě.
Při zápisu adresy do URL bohužel nelze použít stejně přímočarý přístup jako v případě IPv4, kdy se jednoduše místo doménového jména uvede číselná adresa. Dvojtečky jsou v URL používány k oddělení čísla portu od jména či adresy a jejich přítomnost by byla pro interpretující software matoucí. Má-li se v URL vyskytnout IPv6 adresa, musíte ji uzavřít do hranatých závorek. Takže například URL s IPv6 adresou www.nic.cz by vypadalo takto:
http://[2001:1488:0:3::2]/
Podrobně je vše popsáno v RFC 3986: Uniform Resource Identifier (URI): Generic Syntax.
Příslušnost k určité síti nebo podsíti se vyjadřuje prefixem – všechna rozhraní v jedné síti mají stejný prefix (začátek adresy). Jeho délka může být různá, záleží na tom, s jakou podrobností se na adresy díváte. Může vás zajímat jen prefix poskytovatele Internetu (který bude poměrně krátký) nebo o poznání delší prefix určité konkrétní podsítě.
Tento přístup se používá již v současném Internetu pod názvem Classless Inter-Domain Routing (CIDR). Z něj je také převzat způsob, kterým se prefixy zapisují:
IPv6_adresa/délka_prefixu
Délka_prefixu určuje, kolik bitů od začátku adresy je považováno za prefix.
Například 60 bitů dlouhý prefix 12ab:0000:0000:cd3 lze zapsat několika možnými způsoby:
12ab:0:0:cd30:0:0:0:0/60
12ab::cd30:0:0:0:0/60
12ab:0:0:cd30::/60
Nejvhodnější je poslední z nich, protože odpovídá kanonickému tvaru a navíc konstrukcí „::“ logicky nahrazuje závěrečnou část adresy, která je z pohledu prefixu nezajímavá.
Povšimněte si, že do prefixu nepatří ani závěrečná nula ve skupině cd30, protože při délce 60 bitů do prefixu z této skupiny patří jen 12 bitů, čili první tři šestnáctkové číslice.
Tuto nulu však nelze vynechat.
Kdy bychom to udělali, byla by příslušná skupina interpretována jako 0cd3 a zápisem 12ab:0:0:cd3::/60 bychom ve skutečnosti vyjádřili prefix 12ab 0000 0000 0cd, což je krajně matoucí.
Prefix pochopitelně nemusí končit na hranici šestnáctkových číslic.
Například prefix 2000::/3 požaduje, aby první tři bity adresy obsahovaly hodnotu 001 (binárně).
Tomu vyhoví všechny IPv6 adresy, jejichž první číslicí je 2 nebo 3.
Ve zkratce lze použít i zápis, který současně oznamuje jak konkrétní adresu rozhraní, tak délku prefixu (a tudíž adresu podsítě):
12ab:0:0:cd30:123:4567:89ab:cdef/64
Rozdělení aneb typy adres
Obrovský adresní prostor, který má IPv6 k dispozici, rozpoutal hotové orgie kreativity. Vzniklo několik typů sdružujících adresy se společnou charakteristikou. Příslušnost k jednotlivým typům určuje prefix adresy. Dříve se pro tyto určující počáteční bity používal termín prefix formátu (format prefix, FP), novější dokumenty však od tohoto pojmu upouští. Základní rozdělení uvádí tabulka 1 v níž najdete i odkazy na stránky, kde jednotlivé třídy rozebírám podrobněji.
| prefix | význam |
|---|---|
|
nedefinovaná adresa |
|
smyčka (loopback) |
|
unikátní individuální adresa |
|
individuální lokální linkové |
|
skupinové adresy |
ostatní |
individuální globální |
známé prefixy |
|
|
adresy s vloženým IPv4 |
|
lokální adresy pro přechodové mechanismy |
|
Teredo |
|
adresy pro příklady v dokumentech |
|
6to4 |
Jak je vidět, drtivou většinu zabírají globální (celosvětově jednoznačné) individuální adresy. Z jejich prostoru je navíc většina prefixů dosud nepřiřazena, zatím se využívá pouze výše zmiňovaný prefix 2000::/3. Ostatní se ponechávají jako rezerva a očekává se, že budoucí RFC jim přiřknou určitý význam a vnitřní strukturu. Aktuální stav jejich přidělení najdete na adrese https://www.iana.org/assignments/ipv6-address-space
Skupinové adresy jsou snadno identifikovatelné, protože jejich první bajt má v šestnáctkovém zápisu hodnotu ff.
Naproti tomu výběrové adresy nemají přiřazeno žádné speciální rozmezí a přidělují se ze stejného prostoru, jako adresy individuální.
Několika menším oblastem adresního prostoru byl přidělen specifický význam. Celý prefix ::/8 byl původně rezervován pro speciální účely.
Nyní je deklarován jako nepřiřazený, některé adresy v jeho rámci však přiřazeny byly.
Jedná se zejména o individuální adresy :: a ::1.
První se používá pro nedefinovanou adresu.
Říká, že dotyčnému rozhraní dosud nebyla přidělena IPv6 adresa. ::1 je pak adresou lokální smyčky (loopback), kterou počítač-schizofrenik může komunikovat sám se sebou.
Spadají sem také prefixy přidělené pro IPv6 adresy obsahující v sobě IPv4.
Skupinka prefixů identifikuje adresy s omezeným dosahem.
Nejčastěji se setkáte s lokálními linkovými adresami, které jsou jednoznačné vždy jen v rámci jedné linky (jednoho Ethernetu, jedné Wi-Fi buňky, …).
Poznáte je podle prefixu fe80::/10 a najdete je u každého rozhraní se zapnutým IPv6.
Vedle nich dříve existovaly místní individuální lokální adresy s prefixem fec0::/10 jednoznačné v místní síti.
Později však byly zrušeny, proto se jejich prefix v tabulce nevyskytuje.
Nahradily je unikátní individuální lokální adresy s prefixem fc00::/7.
Podívejme se nyní podrobněji na jednotlivé kategorie.
Globální individuální adresy
Tento typ adres je nejdůležitější, protože se jedná o „normální“ adresy – protipól adres současného IPv4. Slůvko globální naznačuje, že identifikují svého nositele v rámci celého Internetu a musí tudíž být celosvětově jednoznačné. Zatím byla definována jen část z nich (prefix 001 binárně), jejíž strukturu definuje RFC 3587: IPv6 Global Unicast Address Format.
Globální adresy jsou přidělovány hierarchicky podle pravidel podobných CIDR ze světa IPv4. To znamená, že poskytovatel Internetu (neboli lokální registr, LIR) obdrží určitý prefix, jehož části v podobě delších prefixů se shodným začátkem pak přiděluje svým zákazníkům. Cílem tohoto přístupu je agregace směrovacích údajů – aby bylo možné při pohledu zvenčí celou poskytovatelovu síť i se všemi zákazníky popsat jediným záznamem ve směrovacích tabulkách, obsahujícím onen společný prefix.
Toto shlukování je velmi důležité, protože významným způsobem zmenšuje velikost směrovacích tabulek. Jemnost členění směrovacích informací přirozeně klesá se vzdáleností od místa určení. Původně se koncept agregace promítal i do struktury adresy, která byla složena z identifikátorů několika úrovní. K praktickému naplnění této vize však nedošlo a reálně používané adresy původní koncept nedodržovaly.
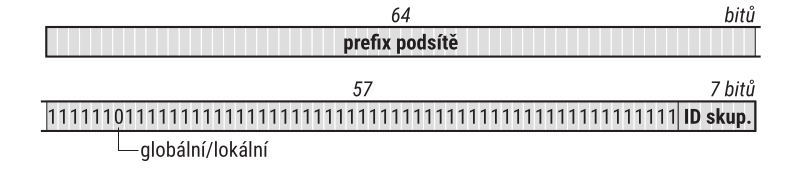
Proto byl opuštěn a RFC 3587 zavedlo maximálně zjednodušený model, v podstatě odpovídající struktuře adresy pro IPv4. Ta má tři části: adresu sítě, podsítě a rozhraní v podsíti. Analogické části má i IPv6 adresa, jen adresa sítě byla přejmenována na globální směrovací prefix. Jejich délky jsou definovány zcela obecně, podle současných pravidel přidělování však globální směrovací prefix měří nejčastěji 48 bitů, adresa podsítě 16 bitů a adresa rozhraní v podsíti 64 bitů. Strukturu globální individuální adresy s nejobvyklejšími délkami jednotlivých částí znázorňuje obrázek
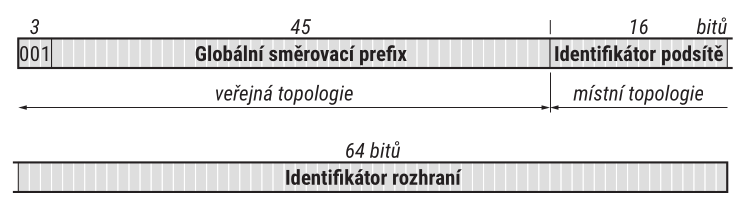
Globální směrovací prefix identifikuje koncovou síť. Je síti přidělen „zvenčí“ lokálním internetovým registrem, čili zpravidla poskytovatelem Internetu. Proto bývá tato část adresy označována jako „veřejná topologie“. Podrobněji se k problematice přidělování globálního směrovacího prefixu vrátím v části 3.14 109 Kromě nejběžnější délky 48 bitů se u malých koncových sítí lze setkat i s prefixy délky 56 či 64 b.
Identifikátor podsítě slouží k rozlišení jednotlivých podsítí v rámci dané sítě. Tato část adresy je, společně s identifikátorem rozhraní, záležitostí správy koncové sítě a používá se pro ni označení „místní topologie“. Délka identifikátoru rozhraní závisí na délce globálního směrovacího prefixu – dohromady musí měřit 64 bitů. Obvyklými hodnotami jsou 16 a 8 bitů, pokud je ovšem globální směrovací prefix 64bitový, na identifikátor podsítě už nezbývá žádné místo a příslušná síť není dělena na podsítě. Identifikátor rozhraní má totiž konstantní délku 64 bitů. Pouze v ojedinělých případech, jako jsou například propojovací podsítě na linkách spojujících pouhá dvě zařízení, má smysl uvažovat o dlouhých adresách podsítě a ponechání jen minimálního prostoru pro identifikátor rozhraní.
Nejběžnější délkou identifikátoru podsítě je 16 b, což umožňuje rozlišit 65 536 podsítí. To stačí i pro opravdu velké sítě. Obecně mívá správce sítě k dispozici nebývalé množství adresního prostoru [1] a díky tomu volné ruce při strukturování koncové sítě a návrhu jejího adresního plánu.
Závěrečný identifikátor rozhraní zabírá celou polovinu adresy, což umožňuje v jedné podsíti rozlišit něco přes \(18 \cdot 10^{18}\) různých rozhraní (tedy miliardy miliard). Motivací k takto velkorysému dimenzování podsítě byla snaha o maximální zjednodušení automatické konfigurace počítačů. Nicméně nelze přehlížet, že AppleTalk zvládal automatickou konfiguraci s jediným bajtem [2] a IPv4 stačí čtyři bajty pro celosvětově jednoznačné adresy. Investovat osm bajtů na dosažení jednoznačnosti v jediné podsíti je zkrátka plýtvání. Důvody, které k tomu vedly, a diskusi o výhodách a nevýhodách najdete v RFC 7421: Analysis of the 64-bit Boundary in IPv6 Addressing.
Ať už si o tom myslíme, co chceme, RFC 4291 jednoznačně stanoví, že pro všechny individuální adresy (s výjimkou adres s prefixem 0::/3) je vyžadována délka identifikátoru rozhraní 64 bitů. Závěrečná část adresy prodělala poměrně zajímavý historický vývoj.
Identifikátory rozhraní
Cílem identifikátoru rozhraní je rozlišit jednotlivá síťová rozhraní v rámci podsítě. IPv6 pro něj vyhradilo celou polovinu adresy, což se jeví jako značně velkorysé. Občas se kolem jeho velikosti vedou vzrušené debaty, ale zatím není patrná významnější snaha ji změnit.
Identifikátor rozhraní může samozřejmě přidělit správce sítě a nastavit jej buď manuálně, nebo prostřednictvím DHCP. Ovšem IPv6 se snaží maximálně usnadnit automatickou konfiguraci, aby si zařízení dokázalo nastavit adresu samo a potřebovalo jen minimum informací ze svého okolí. Jedná se o tak zvanou bezstavovou autokonfiguraci, jejíž popis najdete na začátku dále
Podle původní specifikace měl identifikátor rozhraní obsahovat modifikované EUI-64, které vychází z linkové adresy (podrobnosti viz níže). Měl být snadno odvoditelný a stejný pro všechny podsítě, do nichž se dané zařízení připojilo. Tento přístup ovšem znamená, že identifikátor rozhraní v sobě obsahuje globální identifikátor. To s sebou bohužel nese několik bezpečnostních problémů:
-
Lze sledovat pohyby zařízení v celém Internetu a korelovat jeho komunikaci.
-
Lze z něj odvodit MAC adresu, podle ní poznat výrobce či dokonce typ zařízení a zaměřit se na jeho známé slabiny.
-
Při plošném skenování podsítě lze omezit výběr zkoušených adres.
Proto se modifikované EUI-64 postupně opouštělo. Nejprve se objevily adresy zachovávající soukromí – náhodné krátkodobé identifikátory rozhraní, které si zařízení vytvoří, nějakou dobu používá pro odchozí spojení, následně zahodí a vygeneruje si nový. Vedle nich ovšem zařízení stále má svou stabilní adresu s EUI-64. Už je obtížné je sledovat, protože samo navazuje spojení z náhodných adres, ale ostatní problémy zůstávají. Navíc dočasné adresy způsobují vrásky na čele správců sítě, například při nastavování firewallů nebo dohledávání bezpečnostních incidentů.
S EUI-64 to pak šlo celkem rychle z kopce. RFC 7136 zrušilo speciální význam jakýchkoli bitů v identifikátoru rozhraní individuálních adres a prohlásilo jej za prostý řetězec bitů bez struktury. Poté RFC 7217 definovalo nový způsob generování identifikátoru rozhraní, který je náhodný, ale zároveň stálý pro danou podsíť. A konečně RFC 8064 doporučilo tento způsob používat při bezstavové konfiguraci jako výchozí.
Čili podle aktuálních pravidel by pro každý prefix mělo zařízení mít tyto identifikátory rozhraní:
-
Stabilní, typicky náhodný podle RFC 7217, ale lze použít i jiné varianty, jako je explicitní přiřazení nebo CGA
-
Navíc může používat náhodné krátkodobé podle RFC 4941.
Podívejme se nyní podrobněji na jednotlivé alternativy pro konstrukci identifikátoru rozhraní. Stabilní náhodné identifikátory rozhraní by měly představovat nejběžněji se vyskytující odrůdu. Při jejich návrhu se IETF snažilo, aby vytvářené identifikátory o zařízení nic neprozrazovaly, v různých podsítích se lišily, ale ve stejné podsíti zůstávaly neměnné, tudíž snadněji uchopitelné pro její správce.
Výsledkem je RFC 7217: A Method for Generating Semantically Opaque Interface Identifiers with IPv6 Stateless Address Autoconfiguration (SLAAC), podle nějž si počítač vytvoří identifikátor rozhraní s požadovanými vlastnostmi. Jeho základem je náhodný identifikátor RID vypočtený takto:
RID = F ( prefix, rozhraní, IDsítě, čítač, klíč )
F je hašovací funkce, doporučují například SHA-1 nebo SHA-256. Jako parametr se jí předloží zřetězení prefixu dané podsítě, identifikátoru rozhraní, identifikátoru sítě (např. SSID, toto je jediný nepovinný údaj), čítače (začíná vždy od 0) a tajného klíče, který si zařízení jednou vygeneruje a uloží. Klíč je jedinou informací, kterou je třeba si pamatovat, aby adresa zůstala stabilní.
Jelikož do výpočtu RID vstupují informace o prefixu, bude výsledná hodnota v každé podsíti jiná. Při opakovaném připojení ke stejné podsíti ovšem proběhne stejný výpočet se stejnými hodnotami, takže si zařízení vytvoří shodný identifikátor.
Z RID se pak vezme konec potřebné délky, typicky posledních 64 bitů, spojí s prefixem podsítě a vznikne adresa. Následně se ověří, zda již není obsazena (podrobnosti se dočtete na straně 140).
Pravděpodobnost je sice minimální, ale teoreticky se to stát může. V takovém případě se čítač zvětší o jedničku a celý postup se opakuje. Zařízení si může zapamatovat hodnotu čítače, pro kterou v dané síti uspělo, a příště zde začít rovnou od ní.
RFC 7943: A Method for Generating Semantically Opaque Interface Identifiers (IIDs) with the Dynamic Host Configuration Protocol for IPv6 (DHCPv6) zavádí podobnou metodu i pro výběr adres, které klientům poskytuje DHCPv6 server.
Dočasné adresy zachovávající soukromí vznikly jako reakce na nedostatky původně plánovaného používání EUI-64. Jejich cílem byla ochrana soukromí, tedy ztížení sledování aktivit daného uživatele. Proto jsou náhodné a jejich životnost je omezena na několik hodin až dnů, poté se změní. Jejich definici původně přineslo RFC 3041, později bylo nahrazeno RFC 4941: Privacy Extensions for Stateless Address Autoconfiguration in IPv6.
V současnosti se chystá další aktualizace dokumentu (draft-ietf-6man-rfc4941bis), která doporučuje používat pro generování dočasných adres podobný algoritmus jako RFC 7217 a do parametrů hašovací funkce přidat čas.
Tyto adresy zařízení používá, pokud je iniciátorem komunikace. Jestliže například brouzdáte po webu z počítače používajícího dočasné adresy, váš WWW prohlížeč navazuje spojení s WWW servery z těchto adres. Zítra bude adresa jiná, takže ze zachyceného síťového provozu nebude viditelné, že se serverem komunikuje stejný stroj.
Ovšem je potřeba i nějaký pevný bod, aby se s takovýmto počítačem dalo vůbec navázat spojení. Proto RFC 4941 navrhuje, aby počítač měl jeden pevný identifikátor rozhraní (např generovaný výše popsanou metodou nebo podle EUI-64), pod nímž bude zaveden v DNS. Hlavním smyslem této adresy je sloužit jako cílový bod pro komunikaci navazovanou zvenčí. Vedle ní si navíc počítač generuje náhodné dočasné identifikátory. Adresám z nich odvozeným bude dávat přednost, když sám navazuje spojení s někým jiným. Tyto identifikátory nebudou zavedeny v DNS (jinak by se celý efekt znehodnotil – počítač by sice střídal adresy, ale dal by se poznat podle shodného jména v DNS).
RFC 4291 původně předpokládalo, že předposlední bit v nejvyšším bajtu bude nadále odlišovat globálně platné identifikátory (hodnota 1) od lokálních (hodnota 0). Náhodně generované adresy ovšem tento význam nerespektují a zacházejí se všemi 64 bity stejně. Jejich rozšíření vedlo k opuštění původní představy a k vydání RFC 7136, jež zrušilo speciální význam předposledního bitu a oficiálně prohlásilo identifikátor rozhraní za 64bitovou hodnotu bez jakékoli vnitřní struktury.
Nepředvídatelnost krátkodobých adres a jejich časté střídání komplikují život správcům sítí. Mají-li být případné incidenty později dohledatelné, je třeba ukládat si historii vazeb mezi aktuálně používanými IPv6 adresami a nějakými trvalými identifikátory (např. MAC adresa nebo autentizovaný uživatel). Adresy také přestávají být použitelné pro přístupová oprávnění či nastavování přenosových parametrů.
Jako jedno z možných řešení této situace vzniklo RFC 8273: Unique IPv6 Prefix per Host, které doporučuje vyhradit každému připojenému zařízení prefix délky 64 bitů. V jeho spodní polovině si může střídat adresy podle libosti a mít jich spoustu zároveň, z pohledu správce je stále jednoznačně identifikováno první polovinou adresy. Je to samozřejmě plýtvání, ale řadu věcí usnadní.
Identifikátor rozhraní s modifikovaným z IEEE EUI-64 je z dnešního pohledu již překonaný. Nicméně původní specifikace jej požadovaly a řada zařízení tyto identifikátory stále používá. Proto považuji za užitečné se o nich zmínit. IEEE EUI-64 je standard zaměřený na přidělování globálních (celosvětově jednoznačných) identifikátorů pro rozhraní v počítačových sítích. Jejich délka je 64 bitů a odpovídá tedy délce místa vyhrazeného v IPv6 adrese.
Pokud rozhraní již má přidělen identifikátor EUI-64, do IPv6 adresy se prostě převezme, ale s jednou změnou. Předposlední (druhý nejméně významný) bit v nejvyšším bajtu identifikátoru EUI-64 slouží jako příznak globality. Ve standardním EUI-64 zde hodnota 0 signalizuje celosvětově jednoznačnou adresu, zatímco 1 označuje adresu lokální. IPv6 používá modifikované EUI-64 a hodnotu tohoto bitu invertuje.
Jestliže EUI-64 není k dispozici, snadno se vytvoří.
Asi nejčastějším případem budou sítě založené na některé z variant Ethernetu či bezdrátové sítě Wi-Fi.
V takovém případě mají jednotlivá rozhraní výrobcem přidělené celosvětově jednoznačné 48bitové MAC adresy.
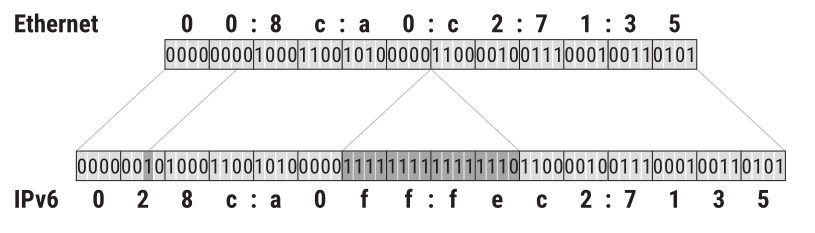
Jejich transformace na modifikované EUI-64 je jednoduchá a standardní: mezi třetí a čtvrtý bajt MAC adresy se vloží 16 bitů s hodnotou fffe.
Kromě toho se obrátí příznak globality.
Takže z MAC adresy 00:8c:a0:c2:71:35 se v IPv6 adrese stane identifikátor rozhraní 028c:a0ff:fec2:7135.
RFC 3972 zavedlo další odrůdu – kryptograficky generované identifikátory rozhraní, jež umožňují zabezpečit objevování sousedů. Vycházejí z veřejného klíče svého vlastníka a znemožňují nepřátelské stanici vydávat se za někoho jiného.
Lokální adresy
Koncept adres, které neplatí v celém Internetu, ale pouze v jeho malé části, zavedlo RFC 1918: Address Allocation for Private Internets. Malou část adresního prostoru IPv4 vyhradilo pro neveřejné adresy, které lze používat v koncových sítích, ale nejsou podporovány za jejich hranicemi. Tyto adresy nejsou celosvětově jednoznačné, každá koncová síť si s nimi může nakládat, jak se jí zlíbí. Původně byly určeny především pro experimenty či pro sítě, které neměly ambice připojit se k Internetu. V současnosti se používají masově v kombinaci s NATem, který jim přístup k Internetu dokáže zprostředkovat, byť s řadou omezení.
IPv6 posouvá tuto myšlenku ještě o krok dál. Zavádí koncept dosahu adres, k němuž se dostaneme později Ten je přínosný především pro skupinové adresy, jejichž sou částí je přímo informace o dosahu. Pro individuální adresy jsou možnosti omezené, nicméně i zde existuje několik typů adres s omezeným dosahem. Jejich přehled uvádí obrázek 3.
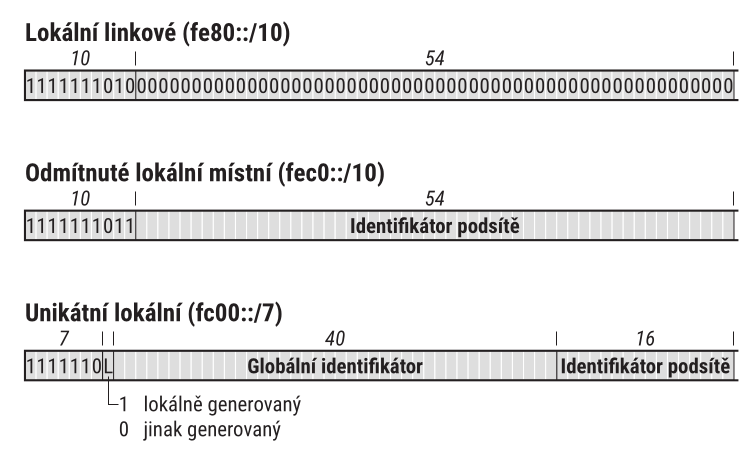
Jsou na něm zobrazeny pouze první poloviny adres, protože druhá polovina ve všech třech případech obsahuje standardní identifikátor rozhraní.
Největší význam mají lokální linkové adresy (link local).
V adresní architektuře mají svou vyhrazenou část – začínají prefixem fe80::/10.
Následujících 54 bitů je nulových, za nimi najdete 64bitový identifikátor rozhraní.
Například pokud si počítač výše popsaným algoritmem vygeneroval identifikátor rozhraní 89ae:b3a5:c8df:fb2a, přidělí mu lokální linkovou adresu:
fe80::89ae:b3a5:c8df:fb2a
Vytvoří si ji sám a pomocí nástrojů automatické konfigurace ověří, že je pro danou linku skutečně jednoznačná.
Počátečních 64 bitů je v ní oficiálně interpretováno jako adresa sítě a podsítě, neslouží však ke směrování. Ani nemohou, protože hodnota těchto bitů je pevně dána a je u všech stejná. Nijak to nevadí, protože dosah lokálních linkových adres je omezen na jedinou linku. Tedy na skupinu počítačů vzájemně komunikujících na linkové úrovni, například propojených Ethernetem či bezdrátovou sítí Wi-Fi. Datagramy nesoucí lokální linkovou adresu jako cíl neprojdou žádným směrovačem, protože za ním již leží jiné linky.
Ze samotné lokální linkové adresy se nedá ani poznat, ke které lince se vlastně vztahuje. Proto se poměrně často vyskytují v kombinaci s identifikátorem rozhraní, díky němuž lze určit, která konkrétní linka je obsahuje. Od adresy se odděluje znakem procento, takže zápis
fe80::2a4:3bff:fee3:35e8%1
představuje lokální linkovou adresu fe80::2a4:3bff:fee3:35e8 nacházející se na lince připojené k rozhraní 1.
Jejich hlavní výhodou je, že počítač si takovou adresu dokáže vygenerovat sám a nepotřebuje k tomu žádnou infrastrukturu. Díky tomu je lokální linková adresa k dispozici vždy. Stačí propojit počítače ethernetovým přepínačem, nemusíte mít žádný směrovač ani server, a přesto mohou rovnou komunikovat prostřednictvím lokálních linkových adres, které si samy vytvoří. V takovéto provizorní síti nebude DNS server, takže uživatelé budou muset zadávat nepříliš přítulné adresy ručně, nicméně mají k dispozici alespoň nějaké spojení.
Všudypřítomnost lokálních linkových adres využívají i některé interní mechanismy související s IPv6. Například automatická konfigurace pomocí DHCP používá pro výměnu zpráv mezi klientem a serverem tyto adresy, najdete je i ve směrovacích tabulkách pro IPv6.
V principu je možné některým částem sítě nepřiřazovat žádné adresy většího dosahu a veškerou komunikaci realizovat jen prostřednictvím lokálních linkových. Typicky se jedná o infrastrukturní spoje, například páteřní linky propojující jednotlivé budovy ve firemní síti. Existuje dokonce specializované RFC, které takovou situaci analyzuje – RFC 7404: Using Only Link-Local Addressing inside an IPv6 Network. Stručně řečeno: zjednodušíte si tím konfiguraci a zvýšíte bezpečnost [3] , ovšem zkomplikujete správu dané části sítě. V praxi se takto adresované páteřní trasy vyskytují jen ojediněle.
Roli velmi podobnou adresám z RFC 1918 hrály ve starších definicích adresního prostoru pro IPv6 lokální místní adresy (site local).
Byl jim přidělen prefix fec0::/10 a jejich platnost byla omezena na jedno „místo“.
Typickým místem je koncová síť organizace připojené k Internetu.
Jenže existují také organizace připojené k Internetu v několika lokalitách téhož města či dokonce v různých městech a státech. Mají být areály MFF UK v na Karlově, v Karlíně, v Tróji a na Malé Straně považovány za čtyři různá místa nebo za jedno místo? Praxe ukázala, že definice místa je vágní a její výklad se velmi liší. Navíc se připojily problémy s konfiguracemi směrovačů a další obtíže při pokusech o reálné použití místních adres.
Výsledkem bylo RFC 3879: Deprecating Site Local Addresses, které místní lokální adresy zamítlo a dokonce zakazuje novým implementacím podporovat speciální zpracování adres s prefixem fec0::/10.
Jejich nástupcem se staly unikátní lokální adresy (unique local addresses, ULA) definované v RFC 4193: Unique Local IPv6 Unicast Addresses.
Poznají se podle prefixu fc00::/7.
Za ním následuje jednobitový příznak L, zda byl prefix adresy přiřazen lokálně (L=1) nebo jinak [4].
Vzhledem k tomu, že všechny v současnosti používané adresy tohoto typu jsou generovány lokálně, mají nastaven příznak L na jedničku a začínají proto prefixem fd00::/8.
Dalších 40 bitů obsahuje globální identifikátor, kterým je náhodně vygenerované číslo [5]. RFC 4193 výslovně zakazuje jeho sekvenční či jinak předvídatelné určení a v části 3.2.2 doporučuje postup vycházející z aktuálního času, adresy generující stanice a algoritmu SHA-1. Čtyřicetibitová položka může nabývat více než bilionu různých hodnot. Pravděpodobnost, že dvojice sítí zvolí stejný globální identifikátor je tedy zhruba stem[10^{12}]. Při milionu koncových sítí je pořád ještě pravděpodobnost, že si alespoň dvě vygenerují stejný globální identifikátor, méně než poloviční.
Prefix společně s globálním identifikátorem dohromady vytvoří obvyklý síťový prefix délky 48 bitů. Za ním následuje v adrese vše podle vyježděných kolejí: 16bitový identifikátor podsítě a 64bitový identifikátor rozhraní.
Proč se globální jednoznačnost těchto adres považuje za tak podstatnou, když se beztak předpokládá jejich lokální využití a stejně jako v případě místních adres nejsou směrovány v internetové páteři?
Vyjděme z výše uvedeného příkladu se čtyřmi pražskými lokalitami MFF UK.
Řekněme, že správci sítě je považují za jedno místo a kromě veřejných adres chtějí používat také lokální adresy.
Vygenerují si tedy prefix, řekněme fdd6:c246:22a9::/48, který ponesou všechny lokální adresy ve spravované síti.
Adresami podsítí pak rozliší jednotlivé lokality a podsítě v nich.
To vše by se snadno dalo zajistit i místními lokálními adresami.
Jednotlivé lokality jsou ale poměrně vzdáleny a k jejich propojení bude využita některá páteřní síť, v daném případě nepochybně PASNET. Po ní budou zároveň směrovány analogické lokální adresy ostatních fakult a univerzit. Unikátní lokální adresy nezpůsobí problém – různé sítě si vygenerovaly odlišné prefixy a budou mít proto jiné adresy. V případě místních lokálních adres, které obsahují jen konstantní prefix, identifikátor podsítě a rozhraní je naproti tomu značná pravděpodobnost kolize. Například lze očekávat, že podsíť 1 si vytvoří více institucí. Jejich propojení sdílenou páteřní sítí by vyžadovalo tunely, virtuální privátní síť či podobnou nadstandardní konfiguraci. Navíc by případné „prosáknutí“ směrovacích informací mohlo způsobit zmatek v jiných částech sítě, zatímco unikátní lokální adresy tímto problémem netrpí.
Ve světě IPv4 se lokální adresy vyskytují obvykle v kombinaci s NATem, který je mění na veřejné a umožní jim tak přístup do Internetu. Nabízí se otázka, jak je na tom IPv6 s překladem adres. Především je třeba říci, že hlavní motivací pro nasazení NATu v IPv4 je nedostatek adres. Obvykle kromě adres mapuje i porty transportní vrstvy6 a umožňuje skrýt celou lokální síť za jednu IPv4 adresu. Tahle potřeba v IPv6 odpadá a pro zdůvodnění použití NATu zbývají jen výškrabečky, jako je třeba nezávislost adres koncové sítě na poskytovateli připojení.
Čili překládat adresy v IPv6 nijak zvlášť nepotřebujeme a jelikož to má řadu nevýhod, oficiálně se používání NATu v IPv6 nedoporučuje. Pro ty, kteří mají pocit, že pro jejich síť bude NAT to pravé, je tu RFC 6296: IPv6-to-IPv6 Network Prefix Translation aneb NPTv6.
Jak vidíte z názvu, nepřekládá jednotlivé adresy, ale celé prefixy sítí. Překlad je bezstavový a obousměrný, dá se navázat i spojení zvenčí do NATované sítě. Na porty nesahá, omezuje se na změnu prefixu. Má dokonce i vypečený mechanismus, kterým upraví část adresy za prefixem tak, aby se nezměnil kontrolní součet pseudohlavičky v TCP a UDP. Díky své oboustrannosti stroje v koncové síti nijak nechrání před případnými útoky zvenčí. Proto je součástí specifikace i doporučení, aby překladač zároveň fungoval jako firewall. Zkrátka jedná se o docela elegantní a velmi zbytečný mechanismus.
Adresy obsahující IPv4
Některé přechodové mechanismy potřebují vyjádřit adresy, které pocházejí ze světa IPv4. Aktuálně se k tomuto účelu používá formát zavedený v RFC 6052: IPv6 Addressing of IPv4/IPv6 Translators a nazvaný adresy s vloženým IPv4 (IPv4-embedded). Využívají skutečnosti, že adresní prostor IPv4 je mnohem menší, proto lze vyčlenit část IPv6 prostoru a použít ji pro reprezentaci IPv4. Tato část je identifikována určitým prefixem a mapovaná adresa vznikne jednoduše tak, že se za prefix připojí IPv4 adresa.
Možné varianty struktury IPv6 adres s vloženými IPv4 adresami znázorňuje obrázek 4.

Začíná prefixem o délce 32, 40, 48, 56, 64 nebo 96 bitů (jiné délky nejsou přípustné), za nímž následuje IPv4 adresa a případně přípona. Pomocí přípony lze v rámci jedné mapované adresy identifikovat jednotlivé části. RFC 6052 však zároveň doporučuje přípony vypustit a používat jen prefixy délky 96 b.
Prefix může být dvou typů – buď se jedná o místní prefix, který přidělí správce sítě ze svého adresního prostoru. Může například vyčlenit pro tento účel jednu podsíť nebo její část. Vzhledem k dřívější interpretaci některých bitů v identifikátoru rozhraní musí bity číslo 64 až 71 (začátek identifikátoru rozhraní) obsahovat samé nuly. Autoři doporučují vytvořit prefix tak, že vyjdete z prefixu délky 64 b a doplníte jej na délku 96 b nulami.
Druhou variantou bude použití univerzálního prefixu (well known prefix):
64:ff9b::/96
definovaného pro tyto účely přímo v RFC 6052.
Pokud se IPv4 adresa nachází až na konci, lze ji zapsat ve standardním tvaru – v desítkové soustavě s bajty oddělenými tečkami.
Adresu s univerzálním prefixem obsahující 147.230.1.2 lze tedy zapsat ve tvaru 64:ff9b::147.230.1.2 nebo 64:ff9b::93e6:102.
Prefix byl zvolen tak, aby byl neutrální vůči kontrolním součtům protokolů UDP a TCP, které kromě údajů z transportní hlavičky zahrnují i IP adresy. Dojde-li k překladu datagramu mezi IPv4 a IPv6, kontrolní součet v transportní hlavičce se nezmění. I univerzální prefix má ale svá omezení – nelze jej používat ve spojení s neveřejnými IPv4 adresami podle RFC 1918. Jestliže ve své síti používáte, byť jen částečně, neveřejné adresy, musíte si definovat vlastní prefix pro jejich vkládání.

Adresy podle RFC 6052 jsou součástí skupiny mechanismů pro překlad mezi IPv4 a IPv6, jehož rámec definuje RFC 6144: Framework for IPv4/IPv6 Translation. Existují a stále vznikají ovšem i jiné překladové mechanismy, které často také vyžadují svůj adresní prostor. Proto RFC 8215 vyčlenilo další prefix:
64:ff9b:1::/48
a přidělilo jej pro lokální adresy využívané různými překladovými mechanismy. Opět se jedná o univerzální prefix, který se nesmí používat ve spojení s neveřejnými IPv4 adresami.
Kromě adres s vloženým IPv4 existují ještě tak zvané IPv4-mapované (IPv4-mapped) adresy, jejichž počátečních 80 bitů obsahuje samé nuly, následuje 16 bitů jedničkových a v posledních 32 bitech je zapsána IPv4 adresa.
Například adresu 147.230.49.73 bychom tímto způsobem vyjádřili jako:
::ffff:93e6:3149
Opět je přípustné psát IPv4 adresu v obvyklé podobě, takže tutéž adresu lze psát i komfortněji:
::ffff:147.230.49.73
Ještě starší specifikace definovaly také IPv4-kompatibilní adresy, které měly počátečních 96 bitů nulových a za nimi následovalo 32 bitů s IPv4 adresou. Už v nich byl k dispozici pohodlný zápis, takže adresa 147.230.49.73 zapsaná jako IPv4-kompatibilní IPv6 adresa má podobu:
::147.230.49.73
IPv4-kompatibilní adresy však byly v RFC 4291 odmítnuty a v současnosti se nepoužívají.
Skupinové adresy
Princip skupin a skupinových adres není žádnou výjimkou již v současném Internetu. Slouží především k distribuci zvukového a obrazového signálu v reálném čase (videokonference, rozhlasové či televizní vysílání a podobně).
Ve skupinách podle IPv6 by nemělo dojít k žádné zásadní revoluci. Strukturu adresy představuje obrázek 6.
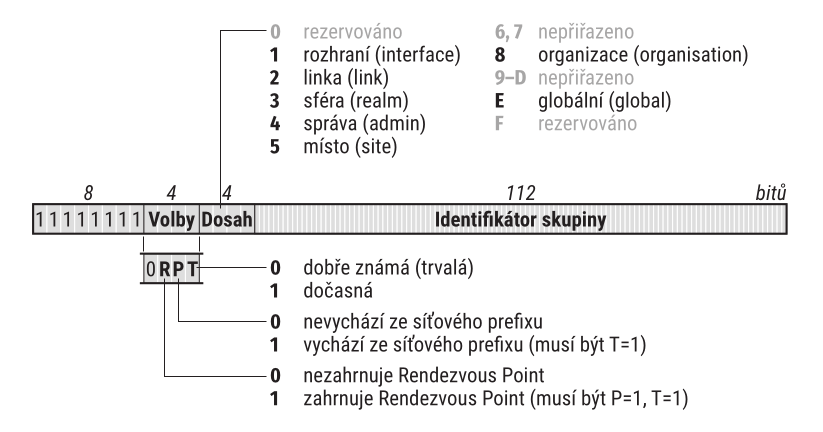
Její největší část slouží k identifikaci skupiny, které mají být data dopravena. K tomu se přidružují dvě krátké podpůrné položky: příznaky a dosah skupiny.
První ze čtyř příznaků je rezervován pro pozdější použití a zatím musí být nulový. Za ním následuje trojice příznaků R (rendezvous point), P (prefix) a T (transient). Vlastní adresní architektura definuje pouze přínzak T. Ostatní dva jsou zavedeny v samostatných dokumentech a jejich popis o chvilku odložím, protože využívají některé další koncepty.
Čtvrtý bit je označován písmenem T (transient) a signalizuje, zda je daný identifikátor skupiny přidělen trvale a jedná se tedy o „dobře známou“ adresu (hodnota 0) nebo zda je přidělen pouze dočasně (T má hodnotu 1). Dobře známé adresy přiděluje IANA, zatímco dočasné si mohou generovat aplikace podle potřeby. Právě jimi se zabývá většina dalších specifikací a návrhů. Zanedlouho se k nim vrátím.
Dosah skupiny sděluje, jak daleko od sebe mohou jednotliví členové být. Jedná se opět o čtyřbitovou položku se šestnácti možnými hodnotami. Nějaký význam byl zatím přidělen zhruba deseti z nich. Podrobnější komentář k dosahům najdete v samostatné části 3.11 Zejména doporučuji vaší pozornosti tabulku 6 obsahující stručnou charakteristiku doposud definovaných dosahů.
| lokální linková | fe80::287c:7fb2:48a5:f4a3 |
|---|---|
individuální |
|
individuální |
|
lokální smyčka |
|
všechny uzly v rámci rozhraní |
|
všechny uzly v rámci linky |
|
vyzývaný uzel |
|
vyzývaný uzel |
|
vyzývaný uzel |
|
přidělená skupina |
|
Nepřiřazené dosahy jsou volně k použití. Určitý význam jim může přidělit například poskytovatel Internetu či správce části sítě. Mělo by přitom zůstat zachováno, že větší hodnota dosahu v adrese bude znamenat doručování paketů do větší [6] části Internetu, než dosahy menší. Například v síti CESNET2, stejně jako v dalších evropských národních akademických sítích, je definován dosah A pokrývající danou národní síť. Skupinové pakety s dosahem A budou proto u nás doručovány všem zájemcům v rámci sítě CESNET2. Lze očekávat, že podobný přístup zavedou i komerční poskytovatelé Internetu a dosah A bude všeobecně znamenat „poskytovatel a jeho zákazníci“.
Jedná-li se o permanentní skupinu (příznak T má hodnotu 0), je její identifikátor stále platný a nezávisí na dosahu.
Například skupina adres ff0x::101 (kde x představuje různé dosahy) byla přidělena NTP serverům.
Důsledkem jsou následující významy adres:
ff01::101 NTP servery na tomtéž rozhraní (čili on sám) ff02::101 NTP servery na stejné lince (např. Ethernetu) ff05::101 NTP servery v daném místě (lokalitě) ff0e::101 NTP servery v celém Internetu
Naproti tomu dočasná skupina má význam jen v rámci svého dosahu.
Takže například skupina s adresou ff15::101 nemá žádný vztah ke skupině, která má stejnou adresu, ale je vytvořena na jiném místě.
Dokonce nemá žádný vztah ani k dočasné skupině se stejným identifikátorem, ale jiným dosahem (např. ff1e::101) ani k trvalým skupinám se stejným identifikátorem.
Nemá tedy nic společného s žádnou z výše uvedených skupin NTP serverů.
Pravidla pro přidělování identifikátorů skupinových adres definuje RFC 3307: Allocation Guidelines for IPv6 Multicast Addresses. Teoreticky je pro identifikátor skupiny k dispozici 112 bitů. Za chvilku ale uvidíme, že některé formáty definují určitou strukturu i v této části adresy a pro skutečný identifikátor skupiny ponechávají jen posledních 32 bitů. RFC 3307 toto omezení kodifikuje a navíc rozděluje skupinové identifikátory do tří oblastí, které najdete v tabulce 2.
| 0 – 3fff:ffff | skupiny přidělené IANA |
|---|---|
4000:0000 – 7fff:ffff |
identifikátory přidělené IANA |
8000:0000 – ffff:ffff |
dynamické, volně k použití |
Rozdíl mezi prvními dvěma skupinami se zdá být poněkud esoterický.
Do první patří případy, kdy IANA definuje celé skupinové adresy, jako například výše zmíněnou adresu ff0x::101 pro NTP servery.
Ve druhé skupině jsou identifikátory, kde IANA definuje pouze samotný skupinový identifikátor, zatímco prefix před ním může být libovolný.
Předpokládá se jejich použití především pro adresy odvozené z individuálních, k nimž se hned dostanu.
Zatím byl definován jediný, 4000:0000 pro proxy sítě, většina definic IANA spadá do první skupiny.
Vybrané adresy a identifikátory přidělené IANA najdete v příloze A.
Do třetí skupiny spadají identifikátory, které si mohou přidělovat podle potřeby jednotlivé aplikace a služby. Existují dva základní přístupy ke správě tohoto typu identifikátorů. Jedním je alokační server, u nějž si aplikace požádají o přidělení skupinového identifikátoru [7]. Podle druhého si berou identifikátory samostatně prostřednictvím vhodného autokonfiguračního protokolu. V každém případě se však jedná o adresy dočasné, jejich příznak T proto musí mít hodnotu 1. Ostatně rozdělení skupinových adres je navrženo tak, aby první bit v čísle skupiny rozdělení skupinových identifikátorů v tabulce 3 kopíroval hodnotu příznaku T.
Skupinové adresy vycházející z individuálních
Příznak P byl definován v RFC 3306: Unicast-Prefix-based IPv6 Multicast Addresses, které zavedlo skupinové adresy vycházející z individuálních. Vznikly s cílem usnadnit generování jednoznačných skupinových adres, aniž by generující stroj musel komplikovaně zjišťovat, zda adresa již někde neexistuje. Proto je jako součást adresy zařazen prefix individuálních adres zdejší sítě. Ten je celosvětově jednoznačný, takže stačí zajistit jednoznačnost identifikátoru v rámci sítě a máme vystaráno. Jedná se vlastně o jeden možný konkrétní formát pro identifikátor skupiny. Jeho uspořádání najdete na obrázku 7.

Začíná osmibitovou rezervovanou položkou, jejíž hodnotou jsou povinně samé nuly. Následuje délka použitého prefixu, tedy počet významných bitů v něm. Nejčastěji bude obsahovat hodnoty 48 či 64. V dalších bitech je uložen prefix odpovídající části sítě, z níž tato skupinová adresa pochází. Jejich počet odpovídá délce z předchozí položky, nanejvýš jich však může být 64. A konečně závěrečných minimálně 32 bitů obsahuje vlastní identifikátor skupiny.
Příznak P s hodnotou 1 oznamuje, že identifikátor skupiny ve skupinové adrese byl vytvořen tímto způsobem. Je-li P=1, musí se jednat o dočasnou adresu, a proto musí mít i příznak T hodnotu 1. Zároveň RFC 3306 požaduje, aby dosah takové adresy nepřesahoval dosah prefixu použitého při jejím vytvoření.
Například Technická univerzita v Liberci má pro své individuální IPv6 adresy přidělen prefix 2001:718:1c01::/48.
Řekněme, že z tohoto prefixu chceme odvodit skupinovou adresu s dosahem pro místo (dosah 5) se skupinovým identifikátorem 7.
Výsledkem bude skupinová adresa:
ff35:30:2001:718:1c01:0:0:7
Její strukturu rozebírá obrázek 8.

Skupinové adresy pro SSM
Speciálním případem skupinově adresovaného vysílání je tak zvaný Source Specific Multicast (SSM).
Slouží pro přenosy dat z jednoho zdroje skupině příjemců, například pro internetové rádio či televizi.
Pro něj byla vyčleněna samostatná část skupinových adres založených na individuálních.
Pozná se podle toho, že délka prefixu i prefix sítě jsou nulové.
Skupinové adresy pro SSM tedy mají prefix ff3x::/96, za nímž následuje 32b identifikátor skupiny.
Jejich strukturu představuje obrázek 9.

Jednoznačnosti zde není těžké dosáhnout, protože skupiny mají vždy jen jediného odesilatele. Stačí, aby on sám si udržel pořádek v jejich identifikátorech. Skupina je jednoznačně určena dvojicí zdrojové adresy svého jediného odesilatele a skupinové adresy.
Skupinové adresy vycházející z rozhraní
Konkurenci adresám založeným na prefixu sítě tvoří skupinové adresy vycházející z rozhraní definované v RFC 4489: A Method for Generating Link-Scoped IPv6 Multicast Addresses. Jejich dosah nesmí být větší než jediná linka, za to si je ale každý stroj může generovat sám bez rizika konfliktu s adresami generovanými jeho sousedy. Adresa tohoto typu totiž obsahuje jeho identifikátor rozhraní, který je na lince vždy jednoznačný. Stačí tedy, aby si udržoval přehled o přidělených identifikátorech skupin, a může si být jist, že všechny používané adresy tohoto typu jsou jednoznačné.

Strukturu adresy vycházející z identifikátoru rozhraní znázorňuje obrázek 10
Volby má nastaveny stejně jako v předchozím případě (P=1, T=1), od adresy vycházející z prefixu sítě se pozná podle hodnoty pole Délka prefixu, jejíž všechny bity obsahují jedničky. Následujících 64 bitů je tvořeno identifikátorem rozhraní, tedy spodní polovinou jeho lokální linkové adresy. Závěrečných 32 bitů nese identifikátor skupiny.
Například si počítač přidělí lokální linkovou adresu fe80::89ae:b3a5:c8df:fb2a, ověří si její jednoznačnost a pokud uspěje, může adresu rozhraní z ní začít používat pro vytváření skupinových adres.
Jejich prefix bude ff32:ff:89ae:b3a5:c8df:fb2a::/96.

Skupinové adresy obsahující RP
Další možný formát skupinového identifikátoru zavádí RFC 3956: Embedding the Rendezvous Point (RP) Address in an IPv6 Multicast Address. Jedná se o skupiny používané ve spojitosti se směrovacím protokolem PIM-SM. Klíčovou roli v něm hraje tak zvané shromaždiště (rendezvous point, RP), v němž koření distribuční strom skupiny. Tento typ skupinových adres v sobě obsahuje adresu shromaždiště, což přináší dva významné klady. Jednak to usnadňuje vytváření jednoznačných adres – stačí udržet v nich přehled v rámci shromaždiště. Především ale kdokoli v celém Internetu si ze skupinové adresy odvodí adresu jejího shromaždiště a ví, kde se do ní přihlásit.
Skupinové adresy obsahující RP nadále rozvíjejí skupinové adresy s individuálním prefixem definované v RFC 3306 (viz obrázek 7.).
Přidávají k nim další příznak R, podle nějž je poznáte.
Skupinová adresa obsahující RP musí mít všechny tři příznaky nastaveny na jedničku, začíná tedy prefixem ff70::/12.
Zabudování adresy RP do skupinové adresy je o něco komplikovanější než v předchozích případech. Adresa RP je rozdělena na dvě části: prefix sítě a identifikátor rozhraní. Prefix sítě je do adresy vložen stejně jako v předchozích případech, zatímco identifikátor rozhraní (označen jako RIID) nahradí spodní čtyři bity v původně rezervované osmibitové položce před délkou prefixu. Výsledek vidíte na obrázku 12.

Z takto vytvořené skupinové adresy lze odvodit adresu jejího RP tak, že síťový prefix použijeme jako její začátek, RIID jako konec a bity mezi nimi vynulujeme.
Například skupina globálního dosahu s identifikátorem 5 odvozená od shromaždiště s adresou 2001:718:1c01:19::8 bude mít adresu:
ff7e:840:2001:718:1c01:19:0:5
Vysvětlení její podoby najdete na obrázku 13, části obsahující adresu shromaždiště jsou v ní zvýrazněny.

Speciální skupinové adresy
RFC 4291 přiděluje několika skupinovým adresám speciální významy. Jedná se o adresu pro všechny uzly (tedy všechna fungující IPv6 rozhraní) v rámci jednoho rozhraní (ff01::1) či v rámci dané linky (ff02::1). Tyto skupiny nahrazují dřívější všesměrové adresy (broadcast).
Do další speciální skupiny patří všechny směrovače. Opět je k dispozici v několika dosazích: v rámci rozhraní (ff01::2), linky (ff02::2) či místa (ff05::2).
Poslední ze speciálních skupinových adres je adresa vyzývaného uzlu.
Těchto skupin je celá řada a jejich adresy mají jednotný tvar ff02::1:ffxx:xxxx.
Hodnota závěrečné trojice bajtů (zde nahrazená písmeny „x“) se vždy převezme z hledané MAC adresy.
Využití najde při objevování sousedů, podrobnosti se dozvíte v části 5.1
Celou přehršel permanentních (dobře známých) skupinových adres definuje RFC 2375: IPv6 Multicast Address Assignments. Zavádí přes 70 adres pro nejrůznější kategorie počítačů a především typy síťových protokolů a služeb. Např. výše zmiňovaná skupina všech NTP serverů (101) pochází právě odtud. Přehled nejvýznamnějších skupinových adres najdete v příloze A
Skupinová adresa se nesmí vyskytnout na místě odesilatele IPv6 datagramu a nesmí být obsažena ani v jeho hlavičce Směrování.
Kromě toho nelze přidělovat adresy ff0x:0:0:0:0:0:0:0, které jsou rezervovány.
Výběrové adresy
Jak již bylo řečeno, výběrové adresy představují asi nejzajímavější novinku v oboru adresování a zároveň velkou výzvu, protože jsou dosud ne zcela probádaným územím. Poskytují velmi zajímavé možnosti. Jejich prostřednictvím lze řešit třeba zdvojování počítačů, směřující ke zvýšení výkonu či spolehlivosti. Mohou se také využít k vyhledání nejbližšího stroje poskytujícího určitou službu.
Například současné nejzatíženější servery bývají ve skutečnosti realizovány skupinou spolupracujících počítačů. Prostřednictvím triků s DNS se dosahuje rozkládání dotazů na jednotlivé členy skupiny. Zbývá však celá řada obtíží (jak rovnoměrně rozkládat zátěž, připojení k Internetu musí mít odpovídající kapacitu apod.).
S výběrovými adresami lze daný problém řešit daleko elegantněji: servery ze skupiny rozmístíte ve vhodných místech Internetu a přidělíte všem stejnou výběrovou adresu. Klient bude posílat pakety na tuto adresu a standardní směrovací mechanismy zajistí, že dorazí vždy k nejbližšímu ze skupiny serverů. Navíc lze složení skupiny průběžně měnit podle potřeby.
Výkladní skříní výběrových adres se staly kořenové DNS servery. Těch by na jedné straně mělo být mnoho, aby docházelo k rozkládání zátěže, služba byla rychle dostupná z libovolné části Internetu a lépe odolávala útokům usilujícím o její zahlcení (DoS, DDoS). Na druhé straně by jich ale mělo být málo, protože jejich adresy musí znát skoro všechny ostatní DNS servery. Seznam adres by proto měl být krátký a velmi konzervativní.
Výběrové adresy právě pro tento případ nabízejí ideální řešení: adres kořenových serverů je třináct, ovšem postupně všechny přešly na výběrové. Počátkem roku 2019 se za jejich třinácti adresami skrývalo celkem přes tisíc serverů. Jejich složení lze navíc průběžně měnit, aniž by se to projevilo na seznamu adres kořenových serverů.
Vzhledem ke své zjevné užitečnosti byl koncept výběrových adres později převzat i pro v IPv4. Základní vlastnosti jsou pochopitelně společné, ovšem rozlehlý adresní prostor IPv6 jejich použití poněkud usnadňuje. Nejčastěji se nasazením výběrové adresy sleduje některý z následujících cílů:
-
Přibližné rozkládání zátěže – dotazy z určité části sítě se sejdou vždy na jednom z uzlů poskytujících výběrově adresovanou službu. Dochází k rozdělení sítě na spádové oblasti.
-
Zrychlení doby odezvy díky kratší cestě mezi klientem a serverem.
-
Lepší odolnost proti útokům typu DoS a DDoS – útočníci jsou schopni „dosáhnout“ jen na servery, v jejichž spádových oblastech se sami nacházejí.
-
Zmenšení počtu adres, na nichž je služba poskytována. Představte si, že seznam adres kořenových DNS serverů by měl tisíc položek a měnil se několikrát za měsíc…
Všude je samozřejmě chléb o dvou kůrkách a některé další vlastnosti výběrových adres nejsou až tak zářivé. Ale než se k nim dostanu, podívejme se, jak jsou vlastně realizovány. Výběrovým adresám nebyla rezervována samostatná část adresního prostoru. Pocházejí ze stejných oblastí jako adresy individuální a mohou se s nimi libovolně míchat. Syntakticky je od sebe nelze rozlišit a ze samotné adresy se nedozvíte, zda je individuální či výběrová. Pokud přidělujete některému rozhraní výběrovou adresu, musí se to příslušným způsobem odrazit v konfiguraci.
Vezmete-li všechna rozhraní, která nesou určitou výběrovou adresu, jistě dokážete najít jistou (co nejmenší) obalovou síť či skupinu sítí, v níž jsou obsažena. Tuto síť lze charakterizovat prefixem P. Například pokud se budou všichni členové výběrové skupiny nacházet ve stejné podsíti, bude P prefix (adresa) této podsítě.
Uvnitř sítě dané prefixem P musí mít výběrová adresa svůj vlastní směrovací záznam, který v jednotlivých směrovačích ukazuje vždy na nejbližšího člena skupiny. Podle těchto záznamů jsou doručovány pakety adresované výběrové skupině. Mimo oblast danou prefixem P pak již není třeba s výběrovou adresou zacházet nijak speciálně a může být zahrnuta do agregovaného bloku adres.
Skutečnost, že výběrové adresy lze směrovat obvyklými metodami (de facto se jedná o cesty k individuálním počítačům, které dnešní směrovací algoritmy a protokoly podporují), je rozhodně dobrou zprávou. Stačí, aby počítač, který se zapojil do výběrové skupiny, ohlásil tuto skutečnost některému směrovači. Ten pak zajistí její distribuci ostatním.
V nejhorším případě jsou příslušníci skupiny natolik rozptýleni, že společný prefix má nulovou nebo zanedbatelnou délku (např. tříbitový prefix 001 příliš nepomůže). V takovém případě by se výběrová adresa přidala mezi globální směrovací informace, což potenciálně představuje obrovský nárůst velikosti směrovacích tabulek páteřních směrovačů. Proto je existence globálních výběrových adres velmi silně omezena a ani do budoucna se neočekává, že by si je snadno mohl zřizovat kdokoli.
Vazba na směrování představuje lesk a bídu tohoto způsobu adresování. Na jedné straně poskytuje pohodlí – aplikace adresuje datagram výběrově a směrování se postará o doručení. Na straně druhé představuje omezení, jimž se musí výběrově poskytované služby přizpůsobit.
Za základní problém lze považovat dynamičnost směrování, které se přizpůsobuje změnám v síti. Pošlete-li sérii datagramů na stejnou výběrovou adresu, mohou být dopraveny různým počítačům. To způsobuje problémy stavovým protokolům, jako je TCP, ale i službám uchovávajícím stav na straně serveru. Možným řešením je rozdělit komunikaci na dvě fáze. V úvodní, která používá výběrové adresy, klient zjistí od serveru jeho individuální adresu a tu pak použije pro vlastní, stavovou fázi přenosu dat.
Ideálem výběrového adresování je však služba, která stavové informace nevyžaduje. Typickým příkladem je právě DNS, kdy dotaz a odpověď představují po jednom datagramu přenášeném protokolem UDP. Čili není co uchovávat, jestliže každý klientův dotaz přistane na jiném serveru, nijak to nevadí. Jen je samozřejmě třeba zajistit konzistenci dat poskytovaných členy výběrové skupiny.
Tím jsme ovšem s problémy způsobovanými směrováním neskončili. Klacky pod nohy výběrového směrování může házet celá řada mechanismů. Směrovací politiky, kdy páteřní internetové směrovače odmítají příliš dlouhé prefixy, a tedy záznamy pro výběrové adresy. Agregace prefixů, která může napáchat na směrování výběrových adres nepěkné škody. Změny ve skupině mohou být vyhodnoceny jako kolísání (flapping) a následně blokovány. Mohou mít také problémy s bezpečnostními testy RPF, které mohou v jejich případě neprávem vyhodnotit zdrojovou adresu jako falšovanou.
Všechny popsané problémy jsou nejožehavější mezi páteřními směrovači Internetu, kde se vyměňují největší objemy směrovacích informací, a proto zde panuje největší přísnost na jejich obsah. Navíc jsou různé části páteře řízeny různými subjekty, jejichž směrovací politiku lze jen těžko ovlivnit. To všechno vede k závěru, že výběrové adresování je v globálním měřítku použitelné jen velmi omezeně pro úzký sortiment vybraných služeb (třeba ony kořenové DNS servery).
Naopak uvnitř menší části sítě (v jednom autonomním systému či v koncové zákaznické síti), kde směrování má zcela pod kontrolou jeden provozovatel, může výběrové adresování představovat rozumně a celkem široce použitelný mechanismus. Výše popsané problémy jsou zde řešitelné bez většího úsilí a lze očekávat i řídké změny topologie, takže datagramy budou zpravidla doručovány témuž stroji.
Určitý extrém představují výběrové adresy v rámci jediné podsítě. U nich pochopitelně nemá smysl mluvit o nejbližším členovi, z pohledu směrování jsou všichni členové stejně daleko. Slouží jako obecné adresy, kdy počítač chce komunikovat se strojem poskytujícím určitý typ služby a nezáleží mu na tom, s kým konkrétně.
Tyto výběrové adresy mají podobu pevně definovaných identifikátorů rozhraní, před nějž se přidá prefix příslušné podsítě.
Zatím byly definovány dvě takové adresy: samé nuly v identifikátoru rozhraní znamenají výběrovou adresu pro směrovače v podsíti a adresa prefix:fdff:ffff:ffff:fffe
identifikuje domácí agenty v podsíti (více se dočtete v kapitole o mobilitě.
Kromě toho RFC 2526: Reserved IPv6 Subnet Anycast Addresses rezervuje horních 128 identifikátorů rozhraní pro různé speciální účely.
Jak konkrétně bude oněch horních 128 adres vypadat závisí na konstrukci adresy (a tedy na prefixu). Specifikace počítá především s identifikátory rozhraní podle EUI-64, v nichž musí bit označující globální/lokální identifikátor obsahovat hodnotu 0 (lokální), protože dotyčná adresa není globálně jednoznačná. Naopak se opakuje v každé podsíti. Strukturu takové adresy vidíte na obrázku 14.
Význam těchto adres je jednotný a postupně je přiděluje IANA. Zatím jedinou přidělenou adresou z tohoto balíku je výše zmíněná adresa pro domácí agenty. Tabulka 3 poskytuje přehled pevně definovaných výběrových adres pro podsíť.
| adresa | význam |
|---|---|
|
směrovače v podsíti |
|
rezervováno |
|
domácí agenti |
|
rezervováno |
Dřívější definice adresní architektury IPv6 zavedla – vzhledem k nedostatku zkušeností – pro výběrové adresy značná omezení. Směly být přiřazeny jen směrovačům a bylo zakázáno uvádět je do zdrojové adresy IPv6 datagramu. V současnosti (počínaje RFC 4291) již tato omezení neplatí.
Pokud by vás zajímal podrobnější rozbor problematiky výběrových adres, určitě si přečtěte RFC 4786: Operation of Anycast Services.
Povinné adresy uzlu
V IPv4 mívalo rozhraní zpravidla právě jednu adresu. Existovaly sice výjimky (např. virtuální WWW servery bývaly svého času realizovány tak, že počítač slyšel na několik IP adres pro totéž rozhraní), ale valná většina uzlů toto pravidlo dodržovala.
IPv6 naproti tomu adresami přímo hýří a nejen umožňuje, že rozhraní bude mít více adres, ale dokonce mu to nařizuje. Existuje totiž jasně definovaná minimální množina adres, ke kterým se každý uzel IPv6 sítě musí hlásit.
Pro koncový počítač se jedná o následující adresy:
-
lokální linková adresa pro každé rozhraní,
-
všechny individuální a výběrové adresy, které mu byly přiděleny,
-
lokální smyčka (loopback),
-
skupinové adresy pro všechny uzly,
-
skupinová adresa pro vyzývaný uzel pro všechny přidělené individuální a výběrové adresy,
-
všechny skupinové adresy, jejichž je členem.
Nejlépe si to demonstrujeme na příkladu.
Vezměme počítač s jednou síťovou kartou, která má dvě individuální adresy – je zapojena do dvou podsítí v rámci organizace.
Jedna má prefix 2001:db8:a319:15::/64 a druhá 2001:db8:a319:3::/64. Kromě toho je členem skupiny ff15::ac07.
Seznam všech adres, na kterých je povinen přijímat data, shrnuje tabulka 4 (již byla uvedena výše jako tabulka 2, zde je zopakovaná). Identifikátory rozhraní si generuje podle RFC 7217, proto se v jednotlivých podsítích liší. Pro každý z nich musí vstoupit do odpovídající skupiny pro vyzývaný uzel.
| lokální linková | fe80::287c:7fb2:48a5:f4a3 |
|---|---|
individuální |
|
individuální |
|
lokální smyčka |
|
všechny uzly v rámci rozhraní |
|
všechny uzly v rámci linky |
|
vyzývaný uzel |
|
vyzývaný uzel |
|
vyzývaný uzel |
|
přidělená skupina |
|
Směrovač se povinně musí hlásit ke všem adresám jako počítač a navíc k následujícím:
-
výběrová adresa pro směrovače v podsíti (pro každé rozhraní, kde funguje jako směrovač),
-
skupinové adresy pro všechny směrovače.
Kdyby výše zmiňovaný počítač byl směrovačem, musel by na rozhraní, které popisujeme, vedle adres uvedených v tabulce 4 poslouchat navíc na adresách, jež shrnuje tabulka 5 Předpokládám v ní, že směrovač působí jako domácí agent. Proto mu byla přidělena výběrová adresa domácích agentů pro obě podsítě.
| směrovače v podsíti | 2001:db8:a319:15:: |
|---|---|
směrovače v podsíti |
|
přidělená výběrová |
|
přidělená výběrová |
|
vyzývaný uzel |
|
vyzývaný uzel |
|
vyzývaný uzel |
|
všechny směrovače na rozhraní |
|
všechny směrovače na lince |
|
všechny směrovače v místě |
|
Dosahy adres
IPv4 původně počítalo výlučně s celosvětově jednoznačnými adresami. Později bylo doplněno ně- kolik lokálních rozsahů (10.0.0.0/8, 192.168.0.0/16 a spol.), které mají platnost omezenu na místní síť a nesmí být předávány do Internetu. Se zavedením skupinových adres se objevila otázka dosahu skupin. Ve světě IPv4 je řešena prostřednictvím životnosti datagramů (TTL). Pro jednotlivé linky lze definovat určitý limit a pokud má datagram TTL nižší než uvedená hodnota, nebude dotyčnou linkou odeslán.
Je celkem zřetelné, že adresy s omezeným dosahem byly do IPv4 doplňovány dodatečně a v podstatě se hledalo, jak využít existující mechanismy pro jejich implementaci. Autoři IPv6 naproti tomu popadli příležitost za pačesy a rozhodli se zapracovat koncept dosahu adres jako jeden ze standardních prvků adresace. Věnuje se mu RFC 4007: IPv6 Scoped Address Architecture.
Intuitivně je pojem dosahu celkem jasný. Formálně je definován jako vymezení topologické oblasti sítě, v níž je daná adresa jednoznačná.
Dostupné dosahy se liší podle druhu adresy. Nejjemnější členění mají skupinové, pro které je podle RFC 7346: IPv6 Multicast Address Scopes definováno sedm stupňů lokality. Najdete je v tabulce 7 kde jsou uvedeny číselné hodnoty jednotlivých dosahů a jejich významy. V případě individuálních adres se rozlišují jen dva stupně: lokální pro linku a globální. Výběrové adresy spadají mezi individuální, takže mají i stejné dosahy.
| dosah | význam |
|---|---|
1=rozhraní |
nepřekročí jediné rozhraní; používá se pro skupinové vysílání do rozhraní pro lokální smyčku (loopback, adresa ::1) |
2=linka |
dosah je omezen na jednu fyzickou síť (např. Ethernet či pouhou sériovou linku se dvěma účastníky) |
3=sféra |
(realm) pokrývá homogenní skupinu linek, které tvoří jeden celek; musí být definována v RFC, typicky v dokumentu typu „přenos IPv6 po XY“ |
4=správa |
nejmenší dosah, který musí být konfigurován správcem (čili nelze jej automaticky odvodit z fyzické topologie či dalších informací); obvykle se jedná o podsíť |
5=místo |
část síťové topologie, která patří jedné organizaci a nachází se v jedné geografické lokalitě, prostě koncová zákaznická síť |
8=organizace |
pokrývá několik míst náležejících téže organizaci, například pobočky jedné firmy v různých městech |
E=globální |
celosvětový dosah |
V popsané hierarchii nemusí nutně platit, že větší dosah pokrývá ostře větší část sítě než dosah menší. V řadě případů mohou být dosahy na několika úrovních totožné – například linka bude v drtivé většině případů shodná se sférou a správní oblastí (podsítí). Zmíněné dosahy budou v reálu platit ve stejné části sítě. Pochopitelně však při postupu hierarchií směrem k většímu dosahu nesmí dojít ke zmenšení odpovídající části sítě.
V souvislosti s dosahy se též objevuje pojem zóna. Jedná se právě o tu část síťové topologie, která odpovídá danému dosahu (adresa je v zóně jednoznačná). Hranice zón procházejí počítači, nikoli linkami. Pochopitelně platí, že celá zóna je vždy zahrnuta do „nadřízené“ zóny většího dosahu, naopak zóny stejného dosahu se nemohou překrývat (jsou buď totožné nebo zcela oddělené). Z hlediska směrování musí být zóna souvislá – pokud by datagram během přepravy opustil zónu, mohlo by dojít k dezinterpretaci jeho adresy.
Rozložení zón (čili dosahů) ilustruje obrázek 3.15 na příkladu jakési sítě zasahující do dvou lokalit. Síť v levé lokalitě zahrnuje tři podsítě, propojené směrovači R1 a R2, síť v pravé lokalitě má jen jednu podsíť. Všimněte si, jak jsou konstruovány zóny odpovídající oběma místům. Nejzapeklitější problém představuje zóna organizace, která má být souvislá. Nabízejí se pro ni dvě základní řešení: Buď bude ve spolupráci s poskytovatelem Internetu tažena jeho páteřní sítí (např. v podobě virtuální sítě), nebo zůstane poskytovatel zcela mimo, organizace si vytvoří tunel propojující směrovače R1 a R3 a použije jej pro přenos skupinových dat mezi oběma pobočkami. Pak by rozhraní směrovačů R1 a R3 zajišťující připojení k Internetu zůstala mimo zónu připojené organizace. Místo nich by do této zóny patřila rozhraní reprezentující propojující tunel. Obrázek 3.15 znázorňuje první variantu, i když pravděpodobnější je druhá.
Hranice některých zón jsou jasně dány z logiky věci – například pro linku. U jiných (jako je třeba místo či organizace) je třeba hranici určit konfigurací odpovídajících zařízení. Například na směrovači R1 je třeba nastavit, že obě rozhraní vnitřní sítě patří do zóny místo, zatímco rozhraní k poskytovateli nikoli.
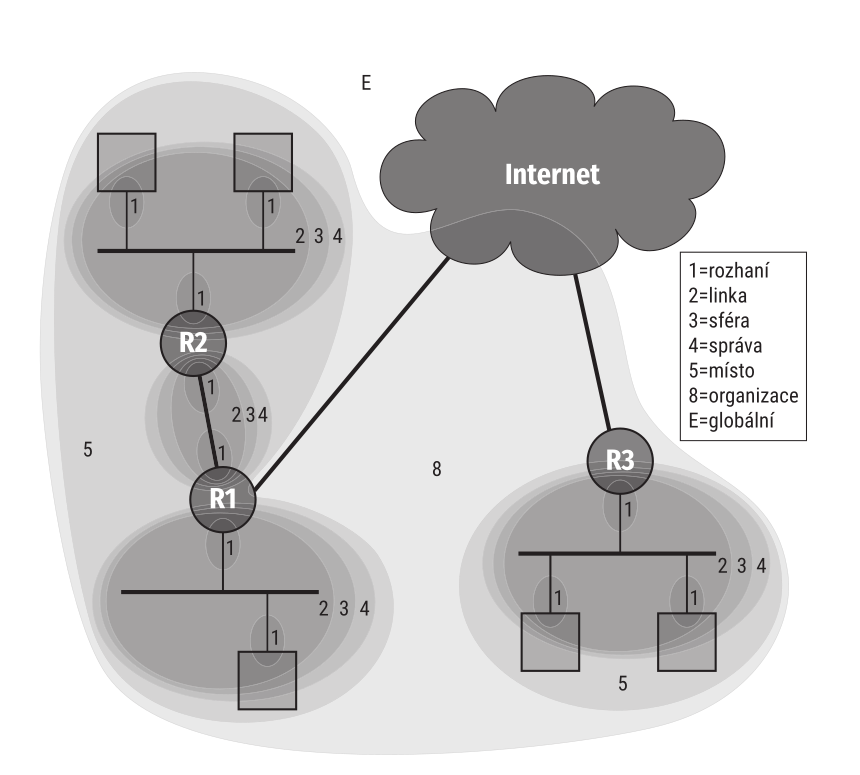
Jelikož je adresa jednoznačná jen v rámci zóny a počítač může být členem několika zón stejného dosahu (například R1 patří do tří různých linkových zón), může dojít k situaci, že se stejná adresa objeví v několika zónách. Aby se tyto adresy daly navzájem rozlišit, zavádí RFC 4007 identifikátory zón. Přestože pracovní verze dokumentu i některé implementace používají identifikátory kombinující dosah a pořadové číslo (např. link1), RFC dává přednost jednoduchosti a doporučuje používat přirozená čísla. Dosah zóny se odvodí z vlastní adresy.
Kompletní zápis adresy pak má tvar adresa%zóna. Například pokud bude spodní Ethernet připojený ke směrovači R1 reprezentován identifikátorem linkové zóny 1, bude mít skupinová adresa pro všechny uzly na této lince plný tvar ff02::1%1.
Identifikátory se přidělují interně v rámci každého počítače a nejsou navzájem synchronizovány se sousedy v téže zóně. Jejich jediným cílem je nabídnout prostředek pro identifikaci zón v rámci jednoho stroje, aby mohly figurovat ve směrovacích tabulkách a podobných strukturách.
RFC 4007 také počítá s konceptem implicitní zóny (s identifikátorem 0), která se dosadí, pokud adresa neobsahuje identifikátor zóny. Příkladem použití mohou být globální adresy, kde existuje jediná zóna a tudíž nemá smysl ji explicitně uvádět.
Drobný komentář si zaslouží změny, jimiž postupně prochází sortiment definovaných dosahů. Zatím směřují spíše ke zjednodušení. Individuální adresy původně obsahovaly ještě dosah lokální pro místo, který odpovídal dosahu 5 u skupinových adres. Ovšem dlouhodobě se nedařilo najít uspokojivou definici „místa“ a projevilo se několik dalších neduhů, proto je RFC 3879 v roce 2004 zrušilo.
Pro skupinové adresy zůstal dosah pro místo zachován, zato zmizela z nabídky podsíť. Dřívější specifikace definovala trojici po sobě jdoucích dosahů (2 pro linku, 3 pro podsíť a 4 pro správu), které v praxi obvykle představovaly tutéž zónu. Každá linka obvykle bývá z hlediska IP podsítí a správcem nastavená hranice přirozeně odpovídá podsíti. Pocit určité nadbytečnosti vyústil ve vypuštění prostředního z těchto tří dosahů.
U některých technologií ale dochází ke spojování linek do celků, proto se v RFC 7346 dosah 3 vrátil, ovšem pod názvem sféra (realm). Význam pro konkrétní technologii musí být definován v příslušném RFC.
Výběr adresy
Přiřazení několika různých adres témuž rozhraní vyvolává nový problém: kterou z nich si vybrat. Představte si modelovou situaci: do svého WWW klienta napíšete www.kdesi.cz, počítač si prostřednictvím DNS zjistí cílovou adresu a dostane řekněme pět odpovědí. Rozhraní, kterým se chystá odeslat data, má přiděleno šest adres. V obou množinách mohou být adresy IPv6 i IPv4. Jaký protokol tedy použít a co vyplnit do hlavičky datagramu? Jakou adresu pro cíl a odesilatele zvolit?
Odpověď poskytuje RFC 6724: Default Address Selection for Internet Protocol version 6 (IPv6), jež stanoví přesný postup pro výběr adres v odesílaném datagramu. Jeho cílem je, aby se všechny implementace IPv6 chovaly konzistentně a předvídatelně. Na druhé straně ovšem ponechává správci stroje možnost ovlivňovat výběr adres nastavením určitých priorit.
Základem algoritmu je výběr z několika kandidátek, případně jejich seřazení podle vhodnosti.
Aplikace, která chce komunikovat, někdy má k dispozici cílovou IP adresu.
Pak je kandidátka jen jedna a výběr cílové adresy odpadá.
Většinou je ale cíl zadán doménovým jménem.
Aplikace v tom případě nejprve zavolá systémovou službu getaddrinfo( ), kterou požádá o převod DNS jména na IP adresu.
Z DNS dotazu vzejde seznam kandidátek na cílovou adresu a ten je následně podle níže uvedených pravidel uspořádán od nejvhodnější adresy po nejméně vhodnou.
Seřazený seznam tvoří výsledek volání getaddrinfo( ), který dostane aplikace.
Ta z něj vybere jednu adresu (slušná aplikace tu první) a požádá o odeslání dat na ni. Nyní je cílová adresa jednoznačně dána a je třeba k ní vybrat nejvhodnější zdrojovou adresu. Kandidátkami na zdrojovou adresu se obvykle stanou všechny individuální adresy přiřazené rozhraní, kterým budou odesílána data k danému cíli. To znamená, že různé cílové adresy mohou mít různé kandidátské sady pro odesilatele. Pokud data odesílá směrovač, může mezi kandidátky zařadit individuální adresy ze všech rozhraní, na kterých předává data. Uplatněním sady pravidel se z kandidátek vybere Miss Odesilatel a ta bude použita v datagramu.
Jestliže se komunikace nezdaří, může aplikace později zkusit další ze seznamu cílových adres a výběr odesilatele se bude opakovat. Přesněji řečeno to může zkoušet i dříve a cíleně volit jiný protokol, viz algoritmus Happy Eyeballs popsaný na straně 223.
K vyjádření místních preferencí slouží tak zvaná tabulka politik (policy table). Její záznamy obsahují po třech položkách: adresní prefix, prioritu (precedence) a značku (label). Vyhledává se v ní podobně jako ve směrovací tabulce – bude použita ta položka, která má nejdelší shodný prefix s posuzovanou adresou. Určí prioritu a značku posuzované adresy.
Priorita obecně vyjadřuje výhodnost dané adresy jako cílové. Vyšší priorita znamená, že této adrese by se měla dát přednost. Prostřednictvím značek pak lze sdělit, že určitý pár adres spolu mimořádně dobře ladí. V jejich případě se posuzuje jen rovnost či nerovnost. Mají-li dvě adresy shodnou značku, dobře se k sobě hodí a bude jim dána přednost.
| prefix | priorita | značka |
|---|---|---|
|
50 |
0 |
|
40 |
1 |
|
35 |
4 |
|
30 |
2 |
|
5 |
5 |
|
3 |
13 |
|
1 |
3 |
|
1 |
11 |
`3ffe::/16 |
1 |
12 |
Vhodným nastavením tabulky politik může správce systému přizpůsobit chování výběru adres svým potřebám [8]. Jestliže tuto možnost nevyužije, použije se implicitní tabulka podle obrázku 16
Za pozornost v ní stojí vysoká priorita implicitní položky (druhý řádek), které vyhoví jakákoli adresa.
Díky ní budou mít například globální IPv6 adresy přednost před adresami 6to4 (viz kapitola 12.3.1 284) s prefixem 2002::/16.
Za chvilku bude jasné proč.
Algoritmus pro volbu adresy definuje dvě sady pravidel. Jedna se vztahuje na zdrojovou adresu a druhá na cílovou. Podívejme se nejprve na výběr odesilatele.
Příslušná pravidla shrnuje obrázek 3.17 potenciálních zdrojových adres SA a SB pro daný cíl. Řada pravidel je symetrických a měla by obsahovat ještě jednou tutéž větu, v níž si SA a SB prohodí role. Pro zjednodušení toto opakování vynechávám a ponechám je na inteligenci čtenáře. Pravidla se aplikují postupně v uvedeném pořadí. Jakmile některé rozhodne, neberou se další v potaz. Jestliže nerozhodne žádné z pravidel, ponechává se volba mezi SA a SB na implementaci.
Porovnáním jednotlivých dvojic z odpovídající kandidátské množiny se určí nejvhodnější zdrojová adresa pro daný cíl. Budeme ji dále označovat odesilatel(cíl).
-
Preferovat totožné adresy.
Pokud je některá z adres totožná s cílovou, vybere ji. -
Preferovat odpovídající dosah.
Jestliže mají zdrojové adresy rozdílný dosah, seřadí si je tak, aby dosah(SA) < dosah(SB). Pak pokud je dosah(SA) < dosah(cíl) vybere SB, jinak vybere SA. -
Vyhýbat se odmítaným adresám. Je-li jedna adresa preferována a druhá odmítána (jedná se o fáze automaticky konfigurované adresy, viz strana 140) vybere preferovanou.
-
Preferovat domácí adresy.
Pokud je jedna z adres zároveň domácí i dočasnou adresou (mobilní počítač je doma – viz kapitola 11 na straně 247) a druhá ne, vybere ji. Jinak je-li SA domácí a SB dočasná, vybere SA. Po implementacích IPv6 je zároveň požadováno, aby poskytly aplikaci způsob, jak toto pravidlo obrátit a preferovat dočasné adresy před domácími. -
Preferovat odchozí rozhraní.
Je-li SA přidělena rozhraní, kterým budou odeslána data k danému cíli, a SB nikoli, vybere SA. -
Preferovat prefix ohlášený směrovačem na cestě.
Pokud byl prefix SA ohlášen směrovačem (viz část 6.1 135), který bude podle směrovací tabulky použit pro odeslání datagramu k danému cíli, zatímco prefix SB byl ohlášen jiným směrovačem, vybere SA. -
Preferovat shodné značky.
Pokud platí značka(SA) = značka(cíl) a značka(SB) ≠ značka(cíl), vybere SA. -
Preferovat dočasné adresy.
Když je SA dočasná adresa chránící soukromí a SB veřejná, vybere SA. Implementace je povinna umožnit aplikaci, aby (s účinností jen pro sebe) nastavila preferenci veřejných adres. Je také doporučeno umožnit správci změnit pravidlo s globální účinností pomocí volby označované Privacy Preference flag. -
Použít nejdelší shodný prefix.
Nerozhodlo-li žádné z předchozích pravidel, použije tu z dvojice zdrojových adres, která má delší shodný prefix s cílem. Do délky prefixu se nepočítá identifikátor rozhraní, jen adresa sítě a podsítě.
Podívejme se na příklad. Řekněme, že počítač má jediné síťové rozhraní, jemuž byly přiděleny následující tři IPv6 adresy:
-
fe80::abcd(lokální linková) -
2002:93e6:3149:1::abcd(6to4) -
2001:db8:1:1::abcd(globální individuální)
Nyní má odeslat datagram na adresu 2002:95aa:37fe:5::4321 a potřebuje z výše uvedené trojice adres vybrat nejvhodnější.
Předpokládejme, že používá výše uvedenou standardní tabulku politik.
První adresa skončí na pravidle číslo 2, protože její lokální linkový dosah je menší než globální dosah cíle.
Mezi druhou a třetí adresou rozhodne až pravidlo číslo 7, z hlediska pravidel 1 až 7 mezi nimi není rozdíl.
Tabulka politik přiřadí cílové adrese značku 2, stejně tak jako druhé adrese.
Naproti tomu třetí adresa obdrží značku 1.
Adresa 2002:93e6:3149:1::abcd má stejnou značku jako cílová, dostane proto přednost a bude použita jako zdrojová adresa.
Seřazení kandidátů na cílové adresy je složitější. Při porovnávání vhodnosti cílových adres se mimo jiné zvažuje, jak dobře se k sobě hodí se zdrojovou adresou. Proto se pro každou z kandidátek nejprve výše uvedeným postupem určí nejvhodnější odesilatel. Seznam kandidátek se pak uspořádá podle následujících pravidel.
-
Vyhýbat se nepoužitelným cílům.
Pokud se o DB ví, že je nedosažitelná, nebo pro ni neexistuje žádná použitelná zdrojová adresa, dá přednost DA. -
Preferovat odpovídající dosah.
Je-li dosah(DA) = dosah(odesilatel(DA)) a dosah(DB) ≠ dosah(odesilatel(DB)), dá přednost DA. -
Vyhýbat se odmítaným adresám.
Pokud je odesilatel(DB) odmítaná adresa a odesilatel(DA) preferovaná, dá přednost DA. -
Preferovat domácí adresy.
Je-li odesilatel pro některou z cílových adres zároveň domácí i dočasnou adresou, dá přednost této cílové adrese. Jinak pokud je odesilatel(DA) domácí adresa a odesilatel(DB) dočasná, dá přednost DA. -
Preferovat shodné značky. Když je značka (odesilatel(DA)) = značka(DA) a značka(odesilatel(DB)) ≠ značka(DB), dá přednost DA.
-
Preferovat vyšší prioritu.
Je-li priorita(DA) > priorita(DB), dá přednost DA. -
Preferovat nativní přenos.
Pokud je DB dosažitelná zapouzdřeným přenosem (např. tunelem), zatímco DA přímo po IPv6, dá přednost DA. -
Preferovat malý dosah.
Je-li dosah(DA) < dosah(DB), dá přednost DA. -
Použít nejdelší shodný prefix.
Pokud jsou obě adresy DA a DB stejného typu (obě IPv6 nebo obě IPv4), dá přednost té z nich, která má delší společný prefix se sobě odpovídající zdrojovou adresou. Délka společného prefixu je shora omezena délkou prefixu zdrojové adresy, aby případná shoda počátečních bitů v identifikátoru rozhraní neovlivňovala výsledky. -
Neměnit pořadí.
Pokud DA bylo v původním seznamu před DB, dá přednost DA.
Tentokrát se porovnává vhodnost dvou potenciálních cílových adres DA a DB. Opět je řada pravidel symetrických, opět rozhoduje první použitelné. Postupným porovnáním jednotlivých dvojic se seznam kandidátek na cíl uspořádá od nejvhodnějších po ty nejméně vhodné.
Jako příklad použijme opět počítač z příkladu pro výběr zdrojové adresy. Řekněme, že DNS dotaz pro určité jméno vydal následující trojici adres:
-
2002:95aa:37fe:5::4321(odesilatel2002:93e6:3149:1::abcd) -
2001:db8:cccc:5::4321(odesilatel2001:db8:1:1::abcd) -
2001:8800:b1a:5::4321(odesilatel2001:db8:1:1::abcd)
V jejich seznamu jsem rovnou uvedl preferované zdrojové adresy, jež jednotlivým kandidátkám vybere výše popsaný algoritmus.
Tentokrát při výběru nepomohou ani značky, protože všechny tři kandidátky mají značku shodnou se svou zdrojovou adresou.
První rozhodnutí přinese až pravidlo 7, protože priorita první adresy je 30, zatímco priorita zbývajících dvou je o deset vyšší.
První adresa je tedy nejhorší.
Mezi druhou a třetí pak rozhodne až pravidlo 9.
Kandidátka číslo 2 má se svým odesilatelem shodný prefix 2001:db8::/32, zatímco kandidátka číslo 3 jen 2001::/16.
Ve výsledku budou proto kandidátky na cílovou adresu seřazeny následovně:
-
2001:db8:cccc:5::4321
-
2001:8800:b1a:5::4321
-
2002:95aa:37fe:5::4321
Jako ideální vychází cílová adresa 2001:db8:cccc:5::4321 a jí odpovídající zdrojová adresa 2001:db8:1:1::abcd, což odpovídá logice – použije se globální individuální adresa ze sítě adresně bližší.
Prefix délky 32 bitů patří lokálnímu registru – obvykle poskytovateli Internetu.
Lze proto očekávat, že přeprava paketů proběhne v rámci jeho sítě, a tedy velmi efektivně.
RFC 6724 představuje druhou generaci algoritmu pro výběr adres. Tu první najdete v RFC 3484, které vyšlo o devět let dříve a dočkalo se dost široké implementace. Zkušenosti s ním získané popisuje RFC 5220: Problem Statement for Default Address Selection in Multi-Prefix Environments: Operational Issues of RFC 3484 Default Rules a odrazily se i ve změnách provedených ve druhé generaci. Za zmínku stojí především rozšíření výchozí tabulky politik, přidání pravidla 6 do výběru zdrojové adresy a otočení pravidla 8 (původně byly preferovány veřejné adresy).
Doposud popsané mechanismy pro volbu adres jsou univerzální a platné pro všechna zařízení podporující IPv6. Tabulka politik dává správci možnost ji ovlivnit a přizpůsobit místní situaci. Problémem ale je, jak do tabulky zasáhnout.
Ruční editace je samozřejmě možná, ovšem krajně nepohodlná. A představa okružní cesty po místních počítačích, pokud by bylo třeba v tabulce něco změnit, vyděsí i otrlé správce sítí netriviální velikosti. RFC 7078: Distributing Address Selection Policy Using DHCPv6 proto přišlo s možností použít pro tento účel univerzální konfigurační protokol DHCPv6 [9]. Definovalo pro ně volbu _Výběr adresy (Address Selection), jejíž formát vidíte zde na obrázku.
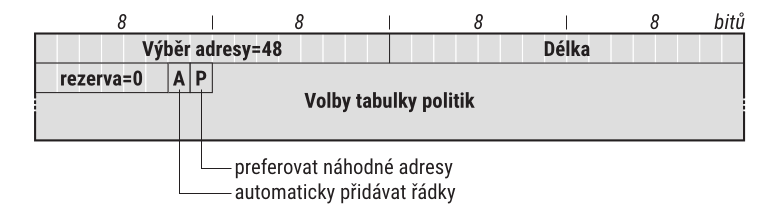
Její hlavní náplň tvoří Volby tabulky politik (Policy Table Options), jimiž jsou jednotlivé položky tabulky. Jejich přesný formát najdete v RFC 7078, nicméně obsahují očekávatelné údaje: prefix, značku a prioritu pro každou z nich. Koncový stroj by standardně měl nahradit svou implicitní tabulku politik tou, kterou získal protokolem DHCPv6. Specifikace ale požaduje, aby bylo možné toto chování vypnout a zachovat si implicitní nastavení.
Volba Výběr adresy pro vás může být zajímavá i v případě, kdy tabulku vlastně ovlivňovat nechcete. Obsahuje totiž příznak P (Privacy Preference), jímž lze řídit, zda počítač má preferovat náhodné adresy zachovávající soukromí (hodnota 1) nebo veřejné globální adresy (hodnota 0). Pokud má volba sloužit k tomuto účelu, ponechte její Volby tabulky politik prázdné a nastavte jen příznaky A a P.
Vícedomovci čili multihoming
Vícedomovci jsou opakem bezdomovců. Příklady známých vícedomovců [10] jasně naznačují, že být vícedomovcem je výhodné. V síťové praxi se tímto pojmem označují zákaznické sítě, které jsou připojeny k několika poskytovatelům připojení. Anglicky se tomuto způsobu připojení říká multihoming.
Jeho hlavním cílem je zajistit zákaznické síti spojení s Internetem i v případě, že u některého z poskytovatelů dojde k výpadku a cesta vedoucí přes něj se přeruší. Vícedomovci se proto stávají především poskytovatelé služeb, jejichž výpadek by byl kritický a znamenal ztrátu, ať už přímou finanční či poškození jména. Například Seznam by jistě nepotěšilo, kdyby byly jeho servery několik hodin nedostupné. Podobně by kterákoli banka špatně nesla ztrátu spojení svého platebního systému.
Podrobněji cíle vícedomovectví pitvá RFC 3582: Goals for IPv6 Site-Multihoming Architectures. Vedle redundance a odolávání výpadkům tu najdete i rozkládání zátěže a zvyšování výkonu díky paralelním přenosům různými sítěmi. Důležitým požadavkem, který zároveň eliminuje některá řešení, je transparentnost vůči vyšším vrstvám. Jestliže dojde k výpadku a provoz je převeden na jiného poskytovatele, měla by navázaná spojení normálně pokračovat a nemělo by to ani omezit možnost navazovat nová v obou směrech.
Dlužno přiznat, že vícedomovectví je problém, především z hlediska směrování. Současná běžná praxe je taková, že síť, která chce být připojena k několika poskytovatelům Internetu, si založí svůj vlastní autonomní systém (AS), opatří si adresy nezávislé na poskytovateli (Provider Independent, PI) a vstoupí do globálních směrovacích tabulek. To znamená, že má svůj záznam na nejvyšší úrovni směrování v páteřních směrovačích Internetu. Ten šíří všichni poskytovatelé, k nimž je připojena. Standardní směrovací mechanismy se postarají o nalezení optimální cesty k ní i o její aktualizace při změnách v síti. Stejné řešení se používá i ve světě IPv4.
Z pohledu IPv6 je tento přístup jasné fuj. Jedním ze základních východisek při návrhu adresní struktury IPv6 bylo, aby umožňovala masivní slučování (agregaci) prefixů a snižovala tak počet záznamů ve směrovacích tabulkách páteřních směrovačů. Dosavadní praxe je ve zřejmém rozporu s tímto cílem.
Na druhé straně je třeba přiznat, že tento přístup zatím jako jediný skutečně funguje a až na škálovatelnost splňuje všechny ostatní požadavky. Navíc nevyžaduje žádné změny v používaných protokolech a systémech, jen opatření administrativního charakteru. Takže zvolejme „Hanba! Hanba! Hanba, že nám nic jiného nezbývá!“
To je velmi hezká myšlenka, ovšem naráží na několik ošklivých problémů. Za prvé mobilita stále není v implementacích příliš dobře podporována. Za druhé se koncový počítač musí dozvědět, že používané spojení bylo přerušeno a že by měl partnerům oznámit změnu adresy. A třetí hřebíček do rakve představuje zabezpečení. Aby se kdokoli nemohl prohlásit za jiný uzel na cestách, následuje po přijetí zprávy „mám adresu X a momentálně jsem k zastižení na adrese Y “ test, zda její odesilatel skutečně přijímá data na obou uvedených adresách. Teď jsme ovšem v situaci, kdy jedna z adres nefunguje a test proto nemůže proběhnout úspěšně.
Mobilita svým konceptem domácí a aktuální adresy ovšem naznačuje cestu, kterou se současné úvahy o vícedomovectví ubírají. Směřují k oddělení dvou rolí, které IP adresa hraje. Slouží jako identifikátor, jehož cílem je jednoznačně určit totožnost počítače, respektive jeho rozhraní. Zároveň ale hraje úlohu lokátoru oznamujícího polohu zařízení v síti a používaného pro směrování datagramů k němu.
Značné úsilí je v současnosti věnováno vývoji mechanismů, které by vedly k rozdělení těchto dvou úloh. Aby každý stroj měl svůj neměnný identifikátor, který by používaly protokoly vyšších vrstev a který by nezávisel na aktuální síťové situaci. Kromě toho by ovšem měl přiřazen jeden či několik dočasných lokátorů využívaných při směrování, které by pružně měnil v závislosti na stavu sítě – při svém pohybu Internetem, při výpadcích a startech linek. Lokátory by sloužily nižším vrstvám komunikační architektury k zajištění vlastních přenosových služeb.
Tento přístup ale znamená významný zásah do významu adresy a vyžaduje úpravu síťové architektury. Některá její část musí provádět mapování mezi identifikátorem a jeho lokátory, vybírat aktuálně nejvhodnější a podobně. Mohla by posloužit distribuovaná databáze podobná DNS, nicméně navržené řešení se neomezuje na jeden konkrétní způsob mapování.
Problematice se věnuje pracovní skupina IETF nazvaná lisp (Locator/ID Separation Protocol). Základní specifikaci protokolu najdete v RFC 6830: The Locator/ID Separation Protocol (LISP), na který pak navazuje řada dalších specifikací. Celý koncept LISP se ovšem zatím nachází v experimentálním stádiu.
O určitý kompromis se snaží koncept nazvaný Shim6 definovaný v RFC 5533: Shim6: Level 3 Multihoming Shim Protocol for IPv6. Slovo „shim“ znamená podložku a mezi programátory se používá pro jednoduchou knihovnu, která převádí jedno aplikační rozhraní na jiné. Docela pěkně to vystihuje jeho funkci.
Shim6 nezavádí samostatný prostor pro identifikátory a neodděluje důsledně identifikátor (ve zdejší terminologii nazývaný ULID, Upper-Layer Identifier) od lokátoru. Místo toho pragmaticky používá v roli identifikátoru první lokátor, s nímž komunikace začala. Počáteční výběr adres proběhne tak jak bylo popsáno v předchozí části a teprve když se komunikace zadrhne, přijde ke slovu Shim6 a pokusí se vybrat nové funkční lokátory. Pro vyšší vrstvy (transportní počínaje) zůstávají nadále v platnosti původní adresy.
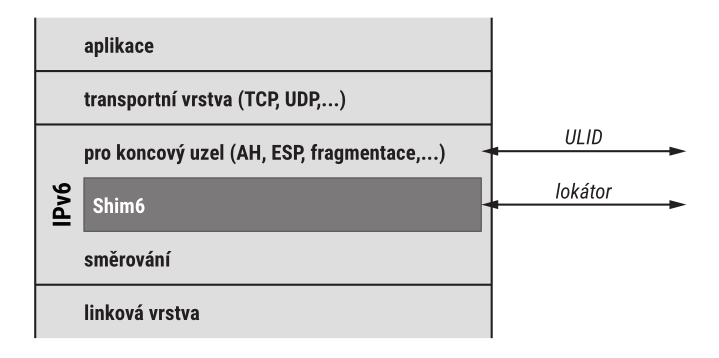
Obrázek znázorňuje umístění Shim6 v komunikační architektuře. Je zařazen do síťové (IP) vrstvy tak, že ji rozděluje na dvě části. Nad ním se nacházejí komponenty síťové vrstvy určené koncovému uzlu – zabezpečení, fragmentace a volby pro příjemce. K případnému přepisování adres dochází až po jejich aplikaci na straně odesilatele, resp. před ní na straně příjemce. Tyto složky se o existenci Shim6 vůbec nedozvědí. Z jejich pohledu (a všech vrstev nad nimi) je Shim6 zcela transparentní. Pod ním se pak nachází ta část IP vrstvy, která zajišťuje směrování.
Shim6 se chová podle známého hesla všech tchýní „Já tady také nemusím být.“ Na začátku komunikace se vůbec neprojeví, ta je zahájena obvyklým způsobem. Spouští se teprve když výměna dat trvá určitou dobu, aby zbytečně nezatěžoval krátkodobou komunikaci (například DNS). Poté proběhne mezi oběma partnery výměna čtyř zpráv, kterými se navzájem informují o svých lokátorech a vytvoří tak zvaný Shim6 kontext. Vše je připraveno pro případ nouze. Jestliže z druhé strany nedorazí odpověď na zprávu vyzývající k vytvoření kontextu, protějšek nepodporuje Shim6 a komunikace bude pokračovat bez něj.
Pokud došlo k vytvoření Shim6 kontextu, protokol se odmlčí a nijak se neprojevuje až do vzniku problému. Jestliže se komunikace zadrhne (což může zjistit Shim6 sám nebo problém ohlásí vyšší vrstva), pokusí se oba partneři najít ze známých lokátorů pár, který funguje. Když se podaří, začne Shim6 přepisovat adresy v odesílaných datagramech a zároveň k nim přidává rozšiřující hlavičku identifikující kontext. Podle ní příjemce pozná datagram upravený Shim6 a přepíše adresy v něm zpět do původní podoby, kterou měly v době zahájení komunikace a která hraje roli identifikátorů. Případné bezpečnostní prvky a další služby jsou uplatněny až na restaurovaný datagram.
Protokol je dost košatý a zahrnuje celou řadu doplňujících prvků. Jimi se například partneři informují o změnách ve složení dostupných lokátorů, umožňuje aplikacím využívat různé kontexty nebo si vyměňovat různé provozní informace.
Přidělování adres
IPv6 se do praxe prosazuje sice pomalu, ale z hlediska administrativního je dnes se svým předchůdcem srovnatelný. Procedura přidělování adres je dnes totožná pro oba protokoly: centrální autoritou je IANA (Internet Assigned Numbers Authority), která přiděluje velké bloky adres regionálním registrům (Regional Internet Registry, RIR). Těch je pět a na jejich počtu se nejspíš hned tak něco nezmění. Zeměkouli mají rozdělenu následovně:
-
AFRINIC Afrika,
-
APNIC Asie a Pacifik,
-
ARIN Severní Amerika,
-
LACNIC Latinská Amerika,
-
RIPE NCC Evropa a Blízký východ.
Jednotlivé regionální registry rozdělují menší bloky registrům lokálním (Local Internet Registry, LIR). Roli lokálních registrů zpravidla zastávají poskytovatelé Internetu. Od nich získávají adresy koncové instituce – zákazníci. Vzhledem k hierarchickému uspořádání přidělovaných rozsahů je zajištěna agregovatelnost.
Pravidla v jednotlivých oblastech oficiálně stanoví vždy příslušný RIR. Tyto organizace však své kroky vzájemně koordinují, navíc jim určitá omezení klade IANA. V praxi jsou proto pravidla všude dost podobná.
Konkrétně v Evropě je aktuálně stanoví dokument ripe-707: IPv6 Address Allocation and Assignment Policy z července roku 2018. Podle něj RIPE NCC alokuje lokálním registrům prefixy délky 29 až 32 bitů (v odůvodněných případech i kratší). Aby jej LIR mohl získat, musí splnit podmínky uvedené v tabulce 7. Stručně řečeno: pokud jste LIR a plánujete do dvou let poskytovat IPv6 služby, máte nárok až na 29bitový prefix.
| 1. | žadatel musí být lokálním registem. |
|---|---|
2. |
Žadatel musí mít plán alokovat části přiděleného IPv6 prostoru dalším organizacím a sítím do dvou let. |
Délku prefixu přidělovaného koncovým sítím ripe-707 konkrétně nepředepisuje, ponechává ji na uvážení poskytovatele (LIR). Zakazuje však přidělování prefixů delších než 64 bitů a v případě prefixů kratších než 48 bitů požaduje zdůvodnění. Nejobvyklejší délkou prefixů pro koncové sítě je 48 bitů, malé sítě (např. domácí) mohou mít prostor omezenější, tedy delší prefix.
Lokální registr má k dispozici alespoň 16 bitů pro rozlišení svých zákazníků. To mu dává prostor přinejmenším pro 65 536 zákaznických prefixů, i když bude přidělovat prefixy délky 48 bitů. Pokud by to bylo málo, politika RIR připouští v odůvodněných případech alokovat lokálnímu registru prefix kratší nebo skupinu prefixů.
Kromě přidělení od LIR může zákazník získat přímo od RIPE NCC i tak zvané adresy nezávislé na poskytovateli (provider independent, PI). Hodí se například pro vícedomovce, o nichž jsem psal v části 3.13 Standardně RIPE NCC přiděluje koncovým sítím PI prefixy délky 48 bitů, požadavek na kratší je nutno zdůvodnit. Aby je však organizace mohla získat, musí se buď stát členem RIPE NCC (a platit nemalý členský poplatek), nebo se dohodnout s některým poskytovatelem, aby se pro ni stal tak zvaným sponzorujícím LIRem (sponsoring LIR) a zprostředkovával styk s RIPE NCC.
Pokud se týče délky zákaznických prefixů, základním dokumentem je RFC 6177: IPv6 Address Assignment to End Sites. Jedná se o poměrně obecný text, který definuje jen základní principy:
-
Pro délku prefixů přidělovaných zákazníkům je rozhodující operativa. Čili pravidla, která si vytvořily regionální internetové registry (RIR), v případě Evropy tedy RIPE NCC.
-
Koncová síť by měla obdržet vždy dostatečný adresní prostor na to, aby nebyla nedostatkem adres nucena k jejich mapování a překladům, tedy k nasazení IPv6 NAT. Mělo by pro ni být snadné získat dostatečný prostor k vytvoření podsítí.
-
Rozhodnutí o délce přiděleného prefixu by mělo vzít v úvahu i snadnost delegace reverzního DNS. V praxi toto doporučení znamená delegovat prefixy, jejichž délka je pokud možno dělitelná čtyřmi, aby zahrnovala vždy všechny bity šestnáctkových číslic tvořících poddomény v reverzním DNS.
-
Dokument se staví proti přidělování adres jednotlivým zařízením, tedy 128 bitů dlouhým prefixům.
RFC 6177 nahradilo dlouhá léta platné (a ne vždy dodržované) RFC 3177. Tato starší verze požadovala, aby se koncovým sítím přidělovaly prefixy jen tří různých délek: 128 bitů pro jednotlivá zařízení, 64 bitů pro sítě, kde jistě nikdy nebude třeba vytvářet podsítě, a 48 bitů pro všechny ostatní, tedy v drtivé většině případů.
Použití unifikované délky prefixů 48 bitů pro valnou většinu koncových sítí má řadu výhod. Usnadňuje změnu poskytovatele či multihoming, protože všichni poskytovatelé přidělují stejně dlouhé prefixy. Vnitřní struktura sítě proto může zůstat stejná u všech prefixů. Odpovídá prefixům již zavedených služeb a protokolů. Usnadňuje vytváření a stěhování reverzních domén pro DNS, protože lokální část adresy je stále stejně dlouhá.
Zároveň je takových prefixů dost – podle analýzy obsažené v RFC 3177 lze na každého obyvatele země přidělit bezmála dvacet 48bitových prefixů, než se začnou objevovat problémy s nedostatkem adres.
Přesto neustále sílily hlasy, že 48bitový prefix je pro některé účely zbytečně velký, že by se mělo šetřit hned od začátku a že by bylo účelné přidělovat malým sítím prefix délky 56 bitů. Ten umožní definovat 256 podsítí (na identifikátor podsítě v něm zbývá 8 bitů), což je pořád ještě pěkná hromádka. Typickým kandidátem pro takovou alokaci je třeba domácí síť připojená ADSL, Wi-Fi nebo jinou technologií. Ta dnes má typicky jednu až žádnou veřejnou IPv4 adresu, ADSL modem v roli NATu a uvnitř jednu síť s počítači adresovanými z neveřejného prostoru. 256 podsítí touto optikou vypadá jako pohádka.
Tomu se postupně přizpůsobila i pravidla jednotlivých regionálních a lokálních poskytovatelů Internetu. Důsledkem je, že lokální síť dnes v závislosti na svých aktuálních a potenciálních potřebách získá prefix délky 48 (běžné sítě), 56 (malé sítě) nebo 64 bitů (velmi malé sítě bez podsítí). Praktické rozšíření IPv6 je však zatím natolik mladé, že reálná pravidla pro jeho poskytování teprve vznikají.
V knize se dále budu držet především 48bitových prefixů, které jsou nejběžnější, nicméně mějte na paměti, že nejsou pravidlem.

Když si současnou praxi přidělování promítneme do struktury adresy, dostaneme v její první polovině hezky uspořádanou kompozici podle obrázku. První část adresy přiděluje IANA regionálním registrům. Její délka kolísá, zpočátku IANA šetřila a přidělovala prefixy délky 23 bitů, v říjnu 2006 ale každý RIR dostal po jednom dvanáctibitovém prefixu. Následuje část přidělovaná regionálním registrem. Zde je hranice poměrně pevná a dohromady s počátkem od IANA tvoří nejčastěji 32bitový prefix přidělovaný lokálním registrům. Ty mají pod kontrolou následujících 16–32 bitů, jimiž definují 48 až 64bitový prefix zákaznické sítě. Zbývající místo do standardní délky prefixu podsítě zaplní identifikátor podsítě o maximální délce 16 bitů.
Podle těchto pravidel bylo do konce roku 2018 přiděleno bezmála čtvrt milionu prefixů délky 32 bitů, z toho zhruba polovina v oblasti spravované RIPE NCC. Celkem v nich byl prostor na téměř šestnáct miliard zákaznických 48bitových prefixů. Aktuální čísla si můžete prohlédnout na adrese:
Přehled prefixů přidělených IANA najdete na stránce:
Jak je vidět, o IPv6 adresy je zájem, i když řada přidělených prefixů zatím slouží jen pro strýčka Příhodu. Reálně byla počátkem roku 2019 ve směrovacích tabulkách ohlašována zhruba polovina přidělených adres. Statistiky vycházející z globálních směrovacích tabulek předávaných pomocí BGP mezi páteřními směrovači Internetu jsou k dispozici na adrese: