V software mikrokontrolérů často používáme stavové stroje, kruhové vyrovnávací paměti a fronty. Tento článek vám poskytne přehled o datové struktuře a provede vás kroky při implementaci kruhových nebo cyklických vyrovnávacích pamětí v zařízeních s malou pamětí. Pokud jste již obeznámeni se základy takových datových struktur, neváhejte přejít do sekce implementace z níže uvedeného obsahu.
Teorie
Výběr vhodné datové struktury nebo algoritmu pro daný problém přichází po hlubokém pochopení základní teorie. V této části projdeme některé klíčové aspekty a problémy implementace kruhové vyrovnávací paměti. Doufejme, že vám to umožní činit informovaná rozhodnutí o výběru datové struktury.
Co to je kruhová vyrovnávací paměť
Kruhová vyrovnávací paměť je datová struktura FIFO, která považuje paměť za kruhovou; to znamená, že indexy čtení a zápisu se po dosažení délky vyrovnávací paměti zacyklí zpět na 0. Toho je dosaženo dvěma ukazateli na pole, ukazatelem „hlava“ a ukazatelem „pata“. Jak jsou data přidávána (zapisována) do vyrovnávací paměti, je inkrementován hlavní ukazatel a podobně, když jsou data odebírána (čtena), je inkrementován koncový ukazatel. Definice hlavy, paty, jejich směr pohybu a místo zápisu a čtení jsou všechny závislé na implementaci, ale myšlenka zůstává stejná.
Takže pro účely této diskuse budeme uvažovat, že zápis se provádí na začátku a čtení na konci. Zde je pěkný GIF z Wikipedie:,
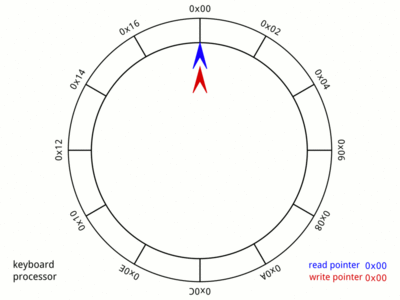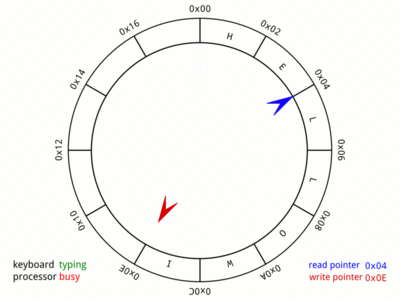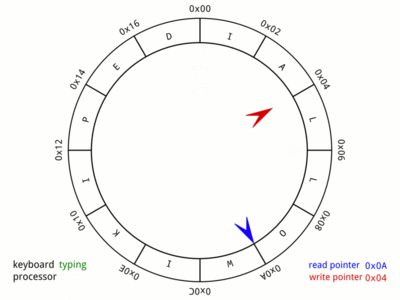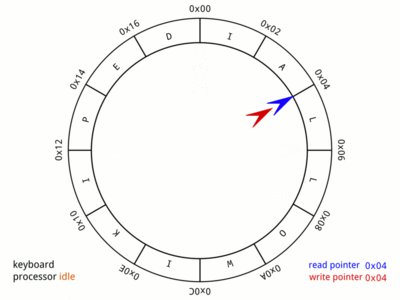
Obrázek mluví za vše. Animace je velmi rychlá a může trvat několik iterací, než si všimnete všech příslušných případů. Věnujte čas tomuto obrázku, protože poskytuje vizuální reprezentaci paměti a ukazatelů, které budou použity v pozdějších částech tohoto příspěvku.
Kde používáme kruhové buffery
Kruhové vyrovnávací paměti jsou nadměrně používány k řešení problému jediné produkce-spotřebitel. To znamená, že jedno vlákno provádění je odpovědné za produkci dat a druhé za spotřebu. Ve velmi nízkých až středních vestavěných zařízeních je výrobcem často rutina služby přerušení (ISR) – možná data produkovaná ze senzorů – a spotřebitel je hlavní smyčkou událostí.
Ale proč to musí být kruhové? proč ne běžné pole? někdo by se mohl divit. Je to velmi častá otázka, která se objeví, když poprvé slyšíte o kruhových bufferech. Ačkoli v průběhu tohoto článku bude potřeba těchto datových struktur velmi jasná.
Synchronizace a závodění
Jsem si jistý, že jste narazili na závodní podmínky kvůli nedostatečné synchronizaci ve vaší programátorské kariéře. Zdá se, že většina lidí si myslí, že se nevztahují na vestavěný svět s nízkou pamětí (který je na pokraji zániku), kde existuje pouze jedno vlákno provádění. Naopak existují i tam (zde vzpomeňte na ISR), vlastně spíše tam.
Pěkná věc na kruhových nárazníkech je jejich elegance. Nevýhodou je, že není snadné jej implementovat bez závodních podmínek. Další dobrá věc je, že je lze implementovat bez potřeby zámků pro prostředí jednoho výrobce a jednoho spotřebitele. Možná to nezní moc, ale nebuďte příliš rychlí v posouzení, potřeby jednoho výrobce a spotřebitele tvoří velkou část celkových aplikací kruhového bufferu.
Díky tomu je ideální datovou strukturou pro vestavěné programy z prostého kovu. Základem je, že musí být správně implementován, aby byl bez rasy.
Řešení problému: Je buffer plný nebo prázdný?
Velkým problémem kruhových vyrovnávacích pamětí je to, že neexistuje žádný čistý způsob, jak rozlišit plný zásobník od prázdných případů. Je to proto, že v obou případech se hlava rovná patě. To znamená, že zpočátku špičky hlavy a ocasu ukazují na stejné místo; když jsou data naplněna do vyrovnávací paměti, hlava se zvýší a nakonec se obtočí (více o tom později) a zachytí konec, když naplníte N-tý prvek (poznámka: není indexován 0) do vyrovnávací paměti N prvků. V tomto okamžiku bude hlava ukazovat na stejné místo jako ocas, ale nyní je vyrovnávací paměť ve skutečnosti plná, nikoli prázdná.
Existuje mnoho způsobů/řešení, jak se s tím vypořádat, ale většina z nich přináší spoustu složitosti a brání čitelnosti. Tento článek představuje metodu, která dává důraz na eleganci v designu.
V této metodě záměrně používáme pouze N-1 prvků ve vyrovnávací paměti N prvků. Poslední prvek se používá (představte si to spíše jako příznak) k rozlišení prázdných a plných případů. Podle této logiky,
-
pokud je hlava rovna patě → buffer je prázdný
-
pokud (hlava + 1) se rovná patě → buffer je plný
V podstatě každé stisknutí zkontroluje podmínku is_buffer_full a každé pop zkontroluje is_buffer_empty.
Kdy přepisovat a kdy zahazovat staré hodnoty
Toto je poslední otázka, která se objevuje ohledně kruhových vyrovnávacích pamětí. Zda musí být nová data zahozena nebo má přepsat existující data, když je vyrovnávací paměť plná. Odpověď je, že neexistuje žádná jasná výhoda jednoho nad druhým a většinou je specifická pro jeho implementaci/použití. Pokud nejnovější data dávají vaší aplikaci větší smysl, použijte metodu přepisování. Na druhou stranu, pokud musí být data zpracována v režimu kdo dřív přijde, je dřív na řadě, zahoďte.
Následující implementace zahodí nová data, když je vyrovnávací paměť plná.
Impementace v C
Nyní, když jsme se zabývali teorií, pojďme pokračovat v implementaci definováním datových typů a následně metod core, push a pop.
V rutinách push a pop vypočítáme ‚další‘ offsetové body k místu, ze kterého bude probíhat aktuální zápis/čtení. Jak bylo uvedeno výše, pokud další umístění ukazuje na místo, na které ukazuje ocas, pak víme, že vyrovnávací paměť je plná a nezapisujeme data do vyrovnávací paměti (vracíme chybu). Podobně, když je hlava rovna ocasu, víme, že buffer je prázdný a nelze z něj nic vyčíst.
Definice datové struktury
typedef struct {
uint8_t * const buffer;
int head;
int tail;
const int maxlen;
} circ_bbuf_t;Zde je naše primární struktura pro zpracování vyrovnávací paměti a jejích ukazatelů.
Všimněte si, že buffer je uint8_t * const buffer.
const uint8_t * je ukazatel na bajtové pole konstantních prvků, to znamená, že hodnotu, na kterou ukazuje, nelze změnit, ale ukazatel samotný ano.
Na druhou stranu uint8_t * const je konstantní ukazatel na pole bajtů, ve kterém se může změnit hodnota, na kterou ukazuje, ale ne ukazatel.
To se provádí tak, že budete moci provádět změny ve vyrovnávací paměti, ale nebudete moci udělat to, že by náhodně osiřet ukazatel. Toto je velmi dobré bezpečnostní opatření, které důrazně doporučuji ponechat tak, jak je.
Vložení dat do kruhového bufferu
Ve většině případů budete vkládání dat do kruhového bufferu volat z ISR.
Funkce push by tedy měl být co nejmenší a celá rutina by měla být uzavřena v kritických sekcích, aby byla synchronizována v prostředí s více vlákny.
Data musí být načtena před zvýšením ukazatele hlavy, aby bylo zajištěno, že spotřebitelské vlákno čte pouze platná data (takové, které volá pop. Viz níže).
Také, pokud si všimnete, držíme jeden bajt jako vyhrazený prostor ve vyrovnávací paměti. Na první pohled se může zdát, že se jedná o chybu, ale pokud se nad tím zamyslíte, uvědomíte si, že jde o technický kompromis. Pokud bych měl použít ten jeden bajt navíc, detekce plných a prázdných případů se stává mírně složitou a psaní kódu, který zvládne všechny hraniční případy, je časově náročné a těžko se ladí, pokud na to přijde.
Takže na závěr, pro malé a pevné datové jednotky si vyhraďte jeden bajt, dokud si ještě můžete zachovat zdravý rozum.
int circ_bbuf_push(circ_bbuf_t *c, uint8_t data)
{
int next;
next = c->head + 1; // next is where head will point to after this write.
if (next >= c->maxlen)
next = 0;
if (next == c->tail) // if the head + 1 == tail, circular buffer is full
return -1;
c->buffer[c->head] = data; // Load data and then move
c->head = next; // head to next data offset.
return 0; // return success to indicate successful push.
}Vybrání dat z kruhového bufferu
Funkce pop rutina je volána procesem aplikace, aby stáhla data z vyrovnávací paměti.
Toto musí být také uzavřeno v kritických sekcích, pokud více než jedno vlákno čte tuto vyrovnávací paměť (ačkoli se to obvykle nedělá).
Zde lze konec posunout na další offset před načtením dat, protože každá datová jednotka má jeden bajt a jeden byte si rezervujeme ve vyrovnávací paměti, když jsme plně načteni. Ale v pokročilejších implementacích kruhové vyrovnávací paměti nemusí mít datové jednotky stejnou velikost. V takových případech se snažíme zachránit i poslední bajt přidáním dalších kontrol a hranic.
V takových implementacích, pokud se tail před čtením přesune, mohou být čtená data potenciálně přepsána nově vloženými daty.
Takže je to obecný osvědčený postup pro čtení dat a poté přesunutí ukazatele paty (tail).
int circ_bbuf_pop(circ_bbuf_t *c, uint8_t *data)
{
int next;
if (c->head == c->tail) // if the head == tail, we don't have any data
return -1;
next = c->tail + 1; // next is where tail will point to after this read.
if(next >= c->maxlen)
next = 0;
*data = c->buffer[c->tail]; // Read data and then move
c->tail = next; // tail to next offset.
return 0; // return success to indicate successful push.
}Typické použití
Myslím, že je celkem zřejmé, že musíte definovat vyrovnávací paměť určité délky a poté vytvořit instanci circ_bbuf_t a přiřadit ukazatel k vyrovnávací paměti a jejímu `maxlen`u.
Je také samozřejmé, že vyrovnávací paměť musí být globální nebo musí být v zásobníku, dokud jej potřebujete používat.
Chcete-li údržbu trochu usnadnit, můžete použít toto makro, ale ohrožuje to trochu čitelnost kódu pro nové uživatele.
#define CIRC_BBUF_DEF(x,y) \
uint8_t x##_data_space[y]; \
circ_bbuf_t x = { \
.buffer = x##_data_space, \
.head = 0, \
.tail = 0, \
.maxlen = y \
}Pokud tedy například potřebujete kruhovou vyrovnávací paměť o délce 32 bajtů, udělali byste ve své aplikaci něco takového,
CIRC_BBUF_DEF(my_circ_buf, 32);
int your_application()
{
uint8_t out_data=0, in_data = 0x55;
if (circ_bbuf_push(&my_circ_buf, in_data)) {
printf("Out of space in CB\n");
return -1;
}
if (circ_bbuf_pop(&my_circ_buf, &out_data)) {
printf("CB is empty\n");
return -1;
}
// here in_data = in_data = 0x55;
printf("Push: 0x%x\n", in_data);
printf("Pop: 0x%x\n", out_data);
return 0;
}Kompletní implementaci výše uvedeného naleznete na adrese goToMain/c-utils v souborech circle-byte-buffer.c a circle-byte-buffer.h.
Doufám, že tento příspěvek pomohl k pochopení kruhových vyrovnávacích pamětí. V příštím příspěvku uvidíme více takových datových struktur a pokročilá rozšíření tohoto kruhového bufferu, který umožňuje push/pop nejen bajtů, ale jakéhokoli datového typu (dokonce i uživatelem definované datové typy) s kontrolou typu a dalšími vymoženostmi.