Původní článek v angličtině na webu Anandtech zde.
Je to rok, co jsme zveřejnili naši poslední paměťovou recenzi; možná nejdelší přestávka, jakou kdy tato část webu viděla. Abych byl upřímný, důvod, proč jsme se zdrželi zveřejňování čehokoli, je ten, že se věci za poslední rok tolik nezměnily – kromě nezbytného posunu směrem k nízkonapěťově orientovaným integrovaným obvodům (~1,30V až ~1,50V) z jako Elpida a PSC. Části těchto typů se nakonec stanou normou, protože paměťové řadiče založené na stále menších procesních technologiích, jako je 32nm Gulftown od Intelu, získávají na trhu trakci.
Zatímco požadavky na napětí se změnily k lepšímu, faktory související s důležitým časováním paměti, jako je CL a tRCD, nezaznamenaly zlepšení; jsme skoro ve stejném bodě jako před rokem. Tehdy Elpida poskytla záblesk slibu se svou Hyper-sérií integrovaných obvodů. Hyper část byla schopna vysokorychlostního provozu s nízkou latencí v tandemu. Bohužel kvůli problémům s dlouhodobou spolehlivostí je Hyper dnes již nefunkční. Corsair a možná Mushkin mají stále dostatek zásob na prodej na chvíli, ale jakmile to bude pryč, je to.

Dnešní návrat paměťové sekce byl podpořen příchodem řady běžných paměťových sad do našich testovacích laboratoří – mnoho sad, které jsme používali pro recenze základních desek, se již neprodává, takže jsme stejně museli aktualizovat náš inventář modulů. Corsair, Crucial a GSkill laskavě poslali vzpomínku ze svých mainstreamových sestav. Původním záměrem bylo podívat se na pár těchto stavebnic.
V průběhu testování těchto sad se však naše zaměření přesunulo od psaní přehledu paměti (ukazuje stejné staré nudné grafy) ke kompilaci něčeho mnohem smysluplnějšího: průvodce optimalizací a adresováním paměti, včetně podrobného pohledu na důležitá časování paměti, a přehled některých méně známých funkcí paměťového řadiče Intel. Jako takový by tento článek měl být velmi poutavým čtením pro ty z vás, kteří se chtějí dozvědět více o některých designech a inženýrství, které umožňují fungování paměti, a o tom, jak může trocha porozumění přinést dlouhou cestu při hledání kreativních způsobů, jak zlepšit výkon paměti…
Synchronní dynamická paměť s náhodným přístupem (SDRAM) je tvořena více poli jednobitových úložných míst uspořádaných do dvourozměrné mřížkové struktury tvořené průnikem jednotlivých řádků (Word Lines) a sloupců (Bit Lines). Tyto struktury podobné mřížce, nazývané banky, poskytují rozšiřitelný paměťový prostor, který umožňuje hostitelskému řídicímu procesu a dalším systémovým komponentům s přímým přístupem do hlavní systémové paměti dočasně zapisovat a číst data do az centralizovaného úložiště.
Když jsou tyto banky spojeny do skupin po dvou (DDR), čtyřech (DDR2) nebo osmi (DDR3), tvoří další vyšší logickou jednotku, známou jako hodnost. 2GB DDR3 Dual Inline Memory Modules (DIMM) jsou bezpochyby nejoblíbenější volbou hustoty mezi dnešními nadšenými uživateli. Většina nových částí tohoto typu je konfigurována jako dvě identické řady po osmi bankách; na jedné straně modulu DIMM jsou umístěny integrované obvody, které tvoří 1. pozici, přičemž 2. řad se nachází na opačné straně modulu. Z tohoto důvodu jednostranné moduly DIMM obvykle obsahují pouze jednu řadu adresovatelného paměťového prostoru.
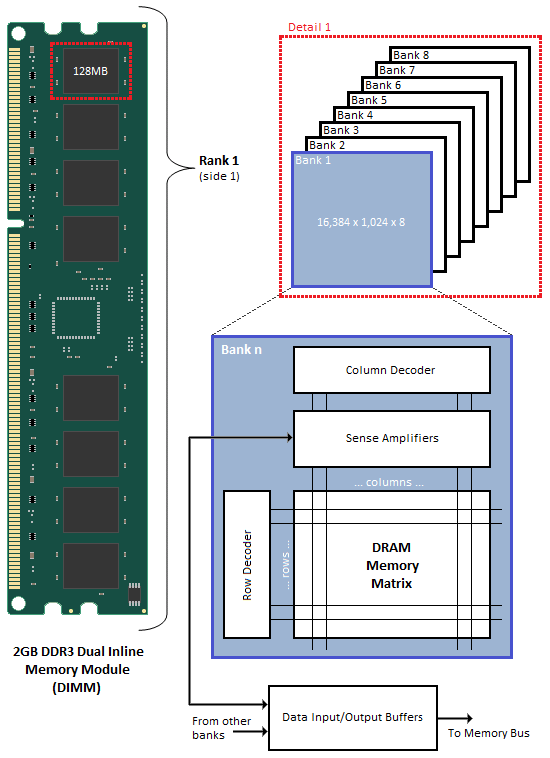
Obrázek ukazuje typické funkční uspořádání paměťového prostoru SDRAM. V případě našeho příkladu oboustranného dvouřadého 2GB SDRAM DIMM bez vyrovnávací paměti obsahuje plně osazený modul celkem 16 integrovaných obvodů, osm na každé straně. Každý IC obsahuje osm bank adresovatelného paměťového prostoru obsahující 16 000 stránek a 1 000 počátečních bodů adres sloupců, přičemž každý sloupec ukládá jediné 8bitové slovo. To zvyšuje celkový paměťový prostor na 128 MB (16 384 řádků/banka x 1 024 adres sloupců/řádek x 1 bajt/adresa sloupce x 8 skládaných bank) na IC. A protože existuje osm integrovaných obvodů na hodnost, 1. pozice má velikost 1 GB (128 MB x 8 souvislých bank) a to samé pro hodnost 2, takže celkový součet 2 GB na modul.
Pokud každý řádek obsahuje 1 K (1 024) počátečních bodů adresy sloupců a každý sloupec ukládá 8 bitů (1 bajt), znamená to, že každý řádek (stránka) má 8 192 bitů (1 024 x 8 bitů) nebo 1 K bajtů na banku. Je důležité pochopit, že každá stránka paměti je segmentována rovnoměrně napříč bankou n každého IC pro přidruženou úroveň. Z tohoto důvodu má každá stránka ve skutečnosti velikost 8KB (1KB x 8 sousedících bank). Takže když mluvíme o hustotě IC, máme na mysli osm různých naskládaných bank a celkový paměťový prostor v nich, zatímco když mluvíme o stránkovém prostoru, ve skutečnosti pracujeme s bankou n rozloženou do celkového počtu IC na hodnost. Nakonec matematika vyjde stejně (8 IC versus 8 bank), ale koncepčně je to kritický rozdíl, který stojí za to uznat, máme-li skutečně pochopit jemnosti a nedostatky adresování paměti.
Nyní vidíme, proč má jádro DDR3 8n-prefetch (kde n označuje počet bank na rank), protože každý přístup ke čtení do paměti vyžaduje minimálně 64 bitů (8 bajtů) dat k přenosu. Je to proto, že každá banka, kterých je pro DDR3 osm, načte ne méně než 8 bitů (1 bajt) dat na žádost o čtení – což odpovídá hodnotě jednoho sloupce dat. Zda systém skutečně využije všech 8 bajtů přenesených dat, je irelevantní. Jakákoli doručená data, která nejsou ve skutečnosti požadována, mohou být bezpečně ignorována, protože se jedná pouze o kopii toho, co je stále uchováno v paměti.
SDRAM lze v mnoha ohledech nejlépe popsat jako jednoduchý stavový stroj (obrázek 2), který je buď nečinný, aktivní nebo přednabíjí jednu nebo více otevřených bank. Jako u každého stroje vyžaduje přechod z jednoho stavu do druhého minimální dobu čekání, než bude systém připraven reagovat na následné požadavky na provedení další práce. Tato zpoždění mají velký dopad na výkon čtení a zápisu SDRAM, a co je důležitější, výkon systému jako celku.
Vzhledem k tomu, že paměťové buňky SDRAM jsou ve skutečnosti jen miniaturní kondenzátory, náboj, který obsahují, se časem přirozeně rozptýlí v důsledku mnoha faktorů, které mohou ovlivnit rychlost úniku, včetně teploty. Výrazné snížení uloženého poplatku může mít za následek ztrátu dat nebo poškození dat. Aby se tomu zabránilo, SDRAM musí být pravidelně obnovována dobíjením náboje obsaženého v každé jednotlivé paměťové buňce. Frekvence, s jakou se tato potřeba obnovy vyskytuje, závisí na křemíkové technologii použité k výrobě matrice paměti jádra a na konstrukci samotné paměťové buňky.
Čtení nebo zápis do paměťové buňky má stejný účinek jako obnovení vybrané buňky vydáním příkazu Refresh (REF). Bohužel ne všechny buňky jsou za normálního provozu čteny nebo do nich zapisovány, a tak je nutné ke každé buňce v poli přistupovat a zpětně zapisovat (obnovit) před uplynutím intervalu obnovy. Ve většině případů obnovovací cykly zahrnují obnovení náboje podél celé stránky. V průběhu celého intervalu je zpřístupněna a následně obnovena každá stránka. Na konci intervalu proces začíná znovu. Typická obnovovací perioda (tREF) je stovky až možná tisíc nebo více hodin.
Všechny banky musí být předem nabity a nečinné po minimální prodlevu RAS Precharge (tRP), než bude možné použít příkaz Refresh (REF). Čítač adres, který je součástí zařízení, dodává adresu banky použitou v průběhu obnovovacího cyklu. Po dokončení obnovovacího cyklu zůstanou všechny banky v přednabitém (nečinném) stavu. Prodleva mezi povelem REF a dalším povelem Aktivace (ACT) nebo následným povelem REF musí být větší nebo rovna době cyklu obnovení řádku (tRFC). Jinými slovy, po obnovení nečinné banky je vyžadováno minimální čekání cyklů tRFC, než může být znovu aktivováno pro přístup.

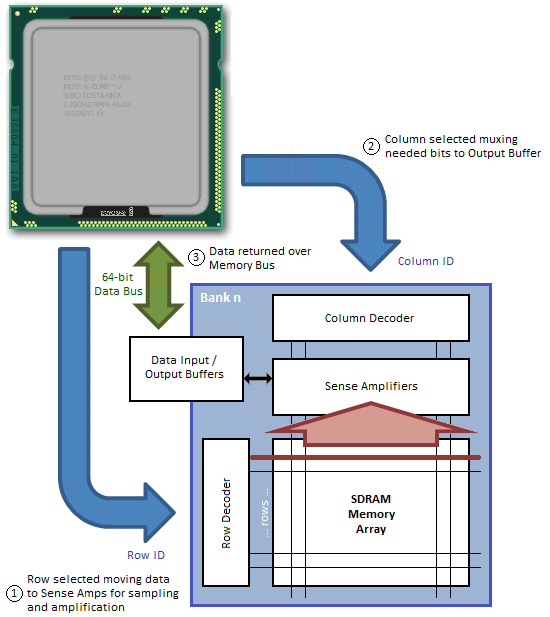
Než je SDRAM připravena reagovat na příkazy čtení a zápisu, musí být nejprve otevřena (aktivována) banka. Paměťový řadič toho dosáhne odesláním příslušného příkazu (ACT), specifikujícího rank, banku a stránku (řádek), ke které má být přístup. Čas pro aktivaci banky se nazývá zpoždění řádků a sloupců (nebo příkazů) a označuje se symbolem tRCD. Tato proměnná představuje minimální dobu potřebnou k zachycení příkazu na příkazovém rozhraní, naprogramování řídicí logiky a načtení dat z paměťového pole do zesilovačů Sense v rámci přípravy na přístup na úrovni sloupců.
Po aktivaci obsahuje otevřená banka v rámci pole Sense Amps úplnou stránku paměti o délce pouhých 8 KB. V tomto okamžiku lze zadat více příkazů čtení (READ) a zápisu (WRI), které určují adresu počátečního sloupce, ke kterému se má přistupovat. Doba načtení bajtu dat z otevřené stránky se nazývá Latence sloupce adresy (CAS) a označuje se symbolem CL nebo tCAS. Tato proměnná představuje minimální dobu potřebnou k zachycení příkazu na příkazovém rozhraní, naprogramování řídicí logiky, vložení požadovaných dat ze zesilovačů Sense do vstupních/výstupních (I/O) vyrovnávacích pamětí prostřednictvím procesu známého jako předběžné načítání, a umístěte první slovo dat na paměťovou sběrnici.
Najednou může být otevřena pouze jedna stránka pro každou banku. Přístup k dalším stránkám ve stejné bance vyžaduje nejprve zavření otevřené stránky. Dokud stránka zůstane otevřená, může paměťový řadič vydávat libovolnou kombinaci příkazů READ nebo WRI, někdy mezi nimi přepínat tam a zpět, dokud nebude otevřená stránka již potřeba nebo dokud nebude vyřízen požadavek na čtení/zápis dat z alternativní stránka ve stejné bance vyžaduje zavření aktuální stránky, aby bylo možné přistupovat k jiné. To se provádí buď vydáním příkazu Precharge (PR) pro uzavření pouze určené banky nebo příkazem Precharge All (PRA) pro uzavření všech otevřených bank v dané řadě.
Alternativně lze příkaz Precharge efektivně kombinovat s poslední operací čtení nebo zápisu do otevřené banky odesláním příkazu Read with Auto-Precharge (RDA) nebo Write with Auto-Precharge (WRA) namísto posledního příkazu READ nebo WRI. . To umožňuje řídicí logice SDRAM automaticky zavřít otevřenou stránku, jakmile jsou splněny určité podmínky: (1) od vydání příkazu ACT uplynulo minimum času aktivace RAS (tRAS) a (2) minimálně čtení to Precharge Delay (tRTP) uplynulo od posledního příkazu READ.
Předběžné nabíjení připraví datové linky a snímací obvody k přenosu uloženého náboje ve Sense Amps zpět na otevřenou stránku jednotlivých paměťových buněk, čímž zruší předchozí destruktivní čtení, čímž je jádro DRAM připraveno na vzorkování další stránky paměti, ke které má být přístup. Čas do předběžného nabití otevřené banky se nazývá zpoždění přednabíjení Row Access Strobe (RAS) a je označen symbolem tRP. Minimální časový interval mezi po sobě jdoucími příkazy ACT do stejné banky je určen dobou cyklu řádku zařízení, tRC, zjištěnou jednoduchým sečtením tRAS a tRP (bude definováno). Minimální časový interval mezi příkazy ACT do různých bank je zpoždění čtení (tRRD).
Proces přesouvání dat do a z paměťového pole a přes paměťovou sběrnici není příliš komplikovaný, i když masivní paralelizace skutečného úsilí může poněkud ztížit plnou představu o tom, co se skutečně děje, bez některých docela stručných vizuálních pomůcek. Pokusíme se vám v tomto ohledu co nejlépe pomoci.
Přístup pro čtení i zápis do DDR[3] SDRAM je orientován na shluky; přístup začíná na vybraném místě a pokračuje v předem naprogramované sekvenci pro délku burstu (BL) 8 bitů nebo 1 bajt na banku. Začíná registrací příkazu ACT a následuje jeden nebo více příkazů READ nebo WRI.
Chip Select (S0#, S1#), jeden pro každou úroveň, buď povolí (LOW) nebo deaktivuje (HIGH) příkazový dekodér, který funguje jako maska, aby zajistil, že příkazy budou ovládány pouze požadovanou úrovní.
Délka každého shluku čtení (tBurst) je vždy 4 hodiny (4T), protože paměť DDR přenáší data dvojnásobnou rychlostí hostitele (4 hodiny x 2 transakce/hodiny = 8 transakcí nebo 8 bitů na banku).
Bity adresy registrované shodně s příkazem ACT se používají k výběru banky a stránky (řádku), ke které se má přistupovat. U našeho hypotetického 2GB DIMM popsaného na straně 2 tohoto článku označují výběry banky BA0-BA2 banku a výběry vstupu adresy A0-A13 označují stránku. K jedinečnému adresování všech osmi bank jsou potřeba tři bity; podobně je potřeba 14 bitů k adresování všech 16 384 (214) stránek.
Bity adresy registrované shodně s příkazem READ nebo WRI se používají k výběru cílového počátečního sloupce pro shluk. A0-A09 vyberte počáteční adresu sloupce (210 = 1 024). Během této operace je také vzorkován A12, aby se určilo, zda byl přikázán Burst Chop (BC) o 4 bitech (A12 HIGH). I když Burst Chop poskytuje pouze polovinu dat oproti běžnému Read Burst, doba pro dokončení přenosu je stále stejná: 4T. Jádro SDRAM jednoduše maskuje záblesk odchozích datových hodin na druhou polovinu celého čtecího cyklu.
Během příkazu Precharge je vzorkován A10, aby se určilo, zda je předběžné nabití určeno pro jednu banku (A10 LOW; BA vybere) nebo všechny banky (A10 HIGH).
Datové vstupní/výstupní kolíky DQ0-DQ63 poskytují 64bitové datové rozhraní mezi řadičem paměti zabudovaným v CPU a každým DIMM. Ti s tříkanálovým procesorem, jako je procesor Intel Core i7-series, pochopí, proč je šířka paměťové sběrnice uváděna jako 192bitová – tři nezávisle provozované kanály, každý s 64bitovým rozhraním, činí 192. provozujete-li Core 2 nebo Core i3/i5, budete si muset vystačit s pouhými dvěma kanály pro celkovou šířku sběrnice 128 bitů.
Každý kanál lze osadit až dvěma moduly DIMM. To znamená, že na kanál by mohly být maximálně čtyři úrovně, za předpokladu, že nainstalujeme pár dvouřadých modulů. Instalace více než jednoho modulu DIMM na kanál nezdvojnásobí šířku pásma paměťové sběrnice, protože moduly umístěné ve stejném kanálu musí soutěžit o přístup ke sdílené 64bitové dílčí sběrnici; přidání dalších modulů má však další výhodu ve zdvojnásobení počtu stránek, které mohou být otevřeny současně (dvojnásobné hodnocení pro dvojnásobnou zábavu!).
Obrázek 3 se pokouší poskytnout pohled shora dolů na minimální cyklus potřebný k prvnímu otevření stránky v paměti a potom čtení dat z aktivované stránky; Obrázek 4 ukazuje totéž, pouze z mnohem zásadnější perspektivy; a Obrázek 5 poskytuje podrobné vyúčtování souvisejícího načasování.
V tomto příkladu předpokládáme, že banka nemá otevřenou stránku, takže je již ve správném předem nabitém stavu pro podporu příkazu pro přístup k nové stránce. Krok 1 vybere banku; Krok 2 vybere sloupec; a Krok 3 vyšle data přes paměťovou sběrnici. 1bitová adresa řádku a 2bitová adresa sloupce jsou vše, co potřebujeme ke čtení dat uložených v našem 2 x 4bitovém x 1 (bankovém) paměťovém poli.
Příkaz Activate vyzve ke směrování zadané adresy stránky, která má být zpřístupněna do dekodéru řádků, kde se spustí zvolená řádka slov, která se objeví na vstupu zesilovačů Sense. Jak již bylo uvedeno, trvá to omezenou dobu – zpoždění řádků a sloupců (nebo příkazů) (tRCD) se používá k naprogramování minimální doby čekání, kterou paměťový řadič umožňuje, aby k tomu došlo, než vydá další příkaz v pořadí. Pokus o nastavení příliš nízkého načasování může vést k neprůkazné operaci, což často vede k poškození dat a dalším problémům s přístupem k datům, které nakonec vedou ke zhroucení systému a dalším chybám aplikací.
Dále adresa sloupce poskytnutá příkazem Read vybere správný bitový řádek a zahájí proces ignorování těch bitů, které nebyly adresovány. Čekání spojené s těmito událostmi je latence CAS (CL nebo tCAS).
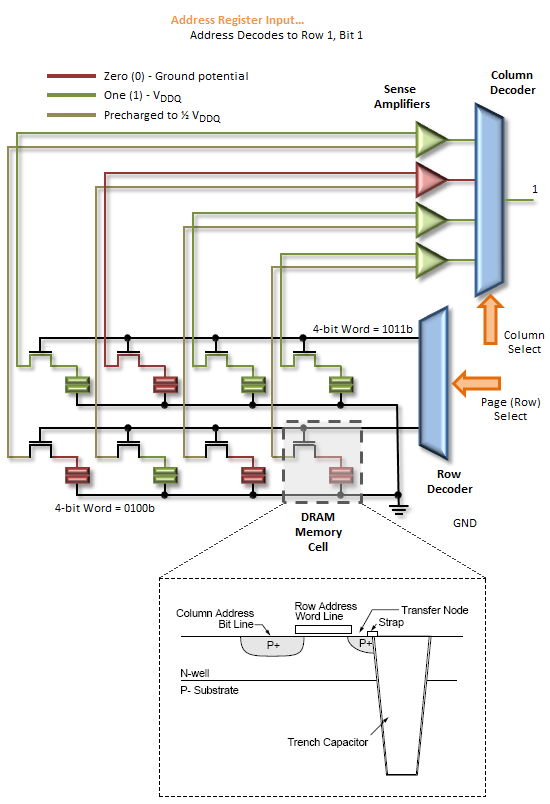
Snímací zesilovače fungují tak, že snímají směr kolísání napětí indukovaného na snímacím vedení, když je aktivován Word Line. Aktivace stránkovacích bran - na spínacím prvku zadržování nahromaděného náboje ve výkopu naplněném dielektrickým materiálem použitým k vytvoření kapacitního úložného prvku paměťové buňky. Když k tomu dojde, snímací čára, počínaje VRefDQ (½ VDDQ), se buď změní pozitivně nebo negativně, v závislosti na potenciálu vzorkované paměťové buňky. Zvýšení napětí kóduje 1, zatímco snížení znamená 0.
Sense Amps nejsou komparátory. Spíše je každý zesilovač Sense propojen s dvojicí paměťových buněk, čímž se dvojnásobně snižuje celkový počet zesilovačů potřebných k jinému snímání celého pole.
Po přečtení je veškerý náboj uložený v paměťových buňkách vymazán. To je to, co je myšleno destruktivním čtením: nejen že zesilovače Sense ukládají stránku do mezipaměti pro přístup, ale nyní uchovávají jedinou známou kopii této stránky v paměti! Přednabití banky přinutí Sense Amps „zapsat“ stránku zpět do pole a připraví snímací řádky pro přístup na další stránku jejich „přednabitím“ na ½ VDDQ. Tím se dosáhne dvou věcí: (1) Vrátí všechny snímací kolejnice na známý, konzistentní potenciál a (2) nastaví předsmyslové síťové napětí na přesně polovinu plné hodnoty VDDQ, čímž zajistí jakýkoli potenciál uložený v buňce, dojde ke kolísání napětí, když je aktivována správná řádka slov.
Každá transakce paměti pro čtení/zápis může být rozdělena podle typu do jedné ze tří výkonnostních přihrádek v závislosti na stavu banky/stránky, ke které se má přistupovat. Tyto přihrádky jsou v pořadí od nejlepší po nejhorší. Z velké části je vše, co můžeme udělat pro zvýšení počtu transakcí s přístupem na stránku nebo snížení počtu transakcí s vynecháním stránky, dobrá věc.
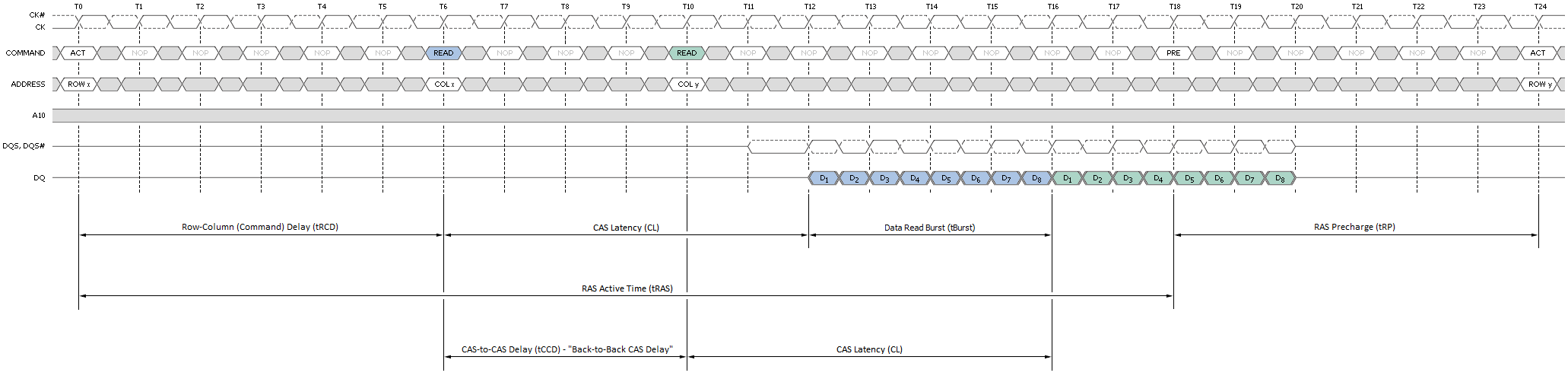
Přístup na stránku je definován jako jakákoli operace čtení nebo zápisu na otevřenou stránku. To znamená, že banka obsahující otevřenou stránku je již aktivní a je okamžitě připravena obsluhovat požadavky. Protože cílová stránka je již otevřena, nominální latence přístupu pro jakoukoli paměťovou transakci spadající do této kategorie je přibližně tCAS (CAS latence zařízení).
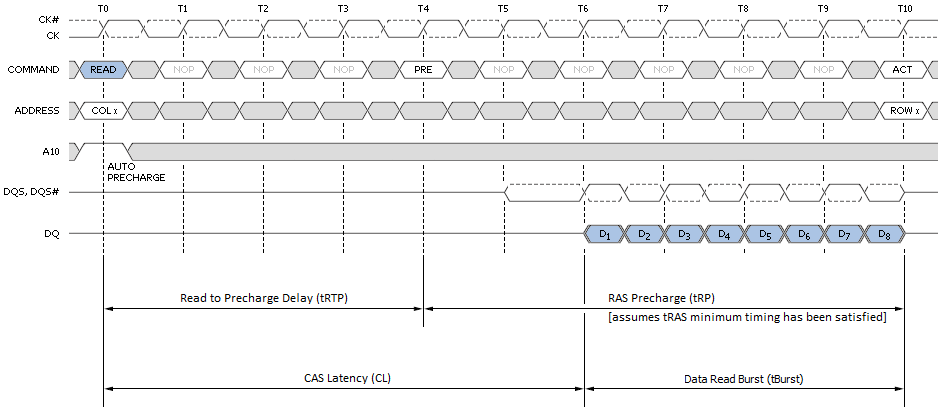
Obrázek 6 ukazuje minimální latenci čtení spojenou s nejlepším scénářem přístupu na stránku. U dílu s latencí CAS 6T čeká paměťový řadič pouze šest krátkých hodin před začátkem návratu dat. Během čtení s automatickým přednabíjením se příkaz Read provede jako obvykle, kromě toho, že aktivní banka začne před koncem shluku předbíjet hodinové cykly CAS-latency (CL). Tato funkce umožňuje, aby byla operace předběžného nabíjení částečně nebo úplně skryta během period cyklů čtení impulzů, v závislosti na CL. Při ladění našich systémů se vždy snažíme nastavit tRTP tak, aby se tRTP + tRP rovnalo CL + tBurst přesně z tohoto důvodu. Jinými slovy, pokud CL a tRP jsou stejné, nastavte 4T pro DDR3 (2T pro DD2).
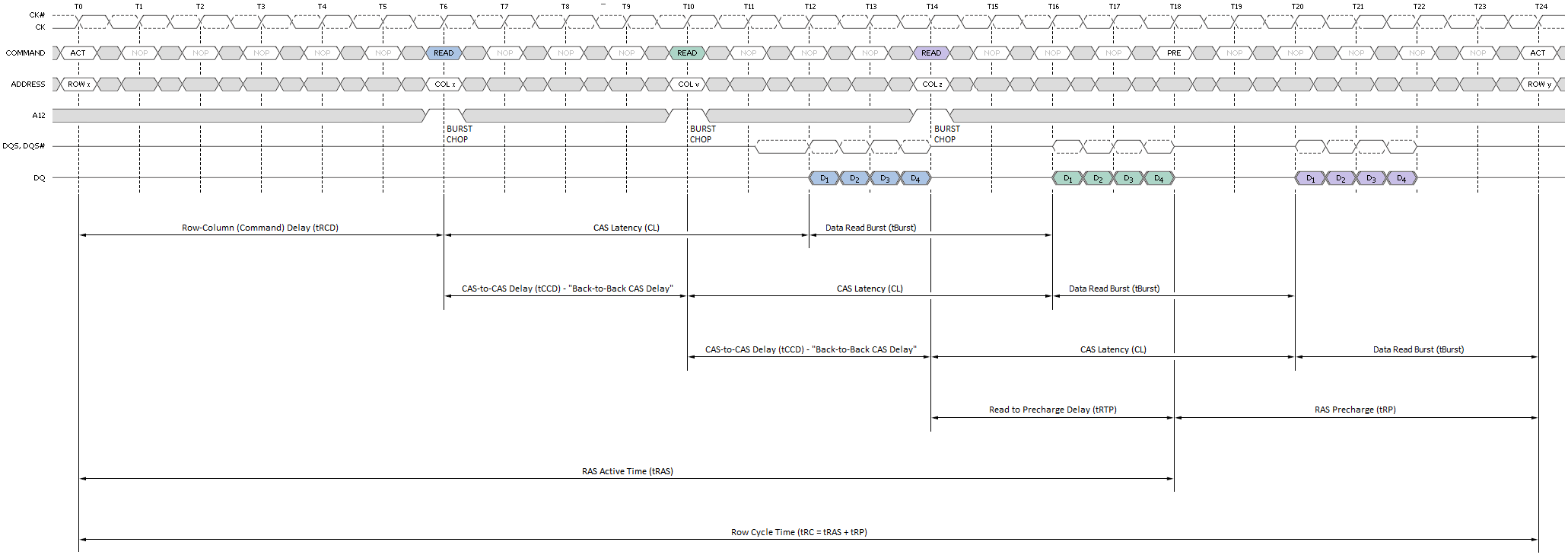
Sekvenční čtení na stejnou stránku činí tyto typy transakcí ještě ziskovějšími, protože každý postupný přístup lze naplánovat na minimálně tBurst (4T) hodiny od posledního. Načasování je zachyceno jako zpoždění CAS-to-CAS (tCCD) a je běžně označováno jako „zpoždění zpětného CAS“ (B2B), jak je znázorněno na obrázku 7. Tato funkce umožňuje extrémně vysoké rychlosti přenosu dat pro celkové délky shluku jedné stránky nebo méně – v našem případě 8 kB.
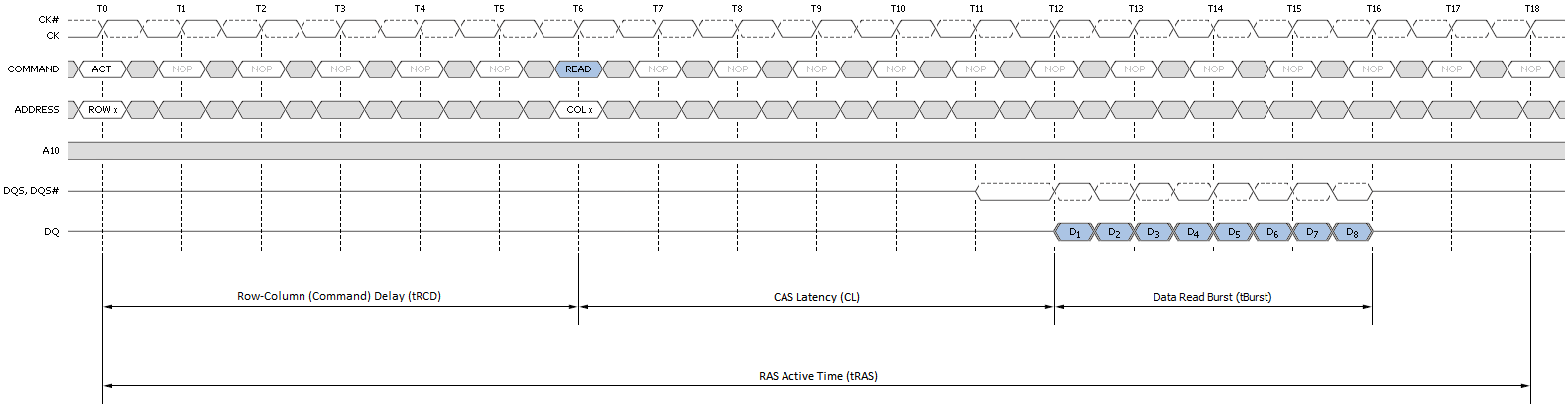
I když to není ideální, je stále preferován přístup s prázdnou stránkou před vynecháním. V tomto případě je banka, ke které se má přistupovat, nečinná bez otevřené stránky. Zdravý rozum nám říká, že jakýkoli pokus o čtení nebo zápis dat na stránku v této bance nejprve vyžaduje, abychom banku aktivovali. Jinými slovy, nominální latence přístupu nyní zahrnuje čas pro otevření stránky – zpoždění řádků a sloupců (nebo příkazů) (tRCD). Jedná se o zdvojnásobení minimální latence přístupu ve srovnání s dobou přístupu na stránku! Nyní uplyne dvanáct cyklů (tRCD + CL), než se vrátí první slovo. Obrázek 8 ukazuje tento detail.
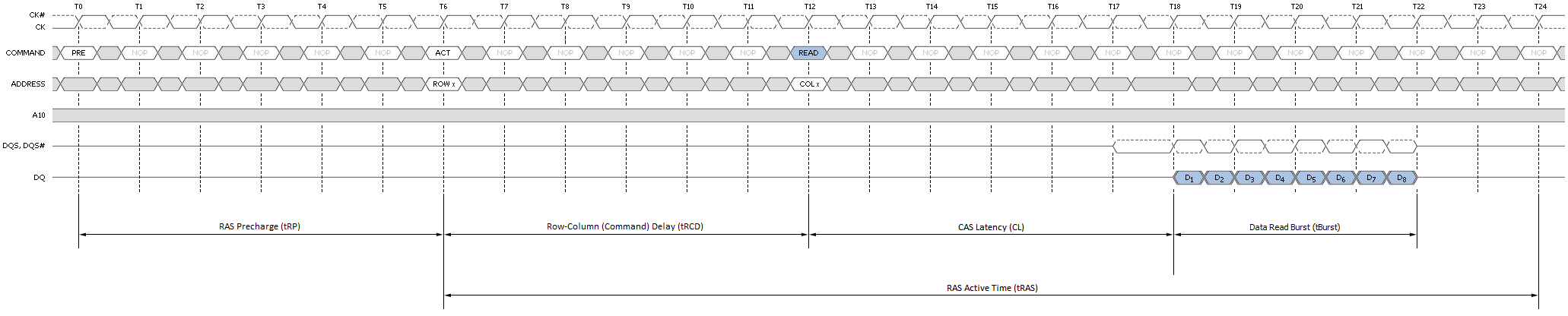
Konečně, jako by relativní trest za přístup s prázdnou stránkou nebyl dost špatný, přichází vynechání stránky. Chyba nastane vždy, když paměťová transakce musí nejprve zavřít otevřenou stránku, aby se otevřela alternativní stránka ve stejné bance. Teprve poté může dojít k zadanému přístupu k datům. První zavření otevřené stránky vyžaduje předběžné nabití, které přidává zpoždění RAS Precharge (tRP) k již tak zdlouhavé operaci. Jak můžete vidět na obrázku 9, nominální latence přístupu tohoto typu je trojnásobná oproti jedné operaci otevření stránky!
Relativní poměr zisk/ztráta pro každý typ přístupu lze rychle vyhodnotit jednoduše prostřednictvím zběžného přehledu nejzákladnějších časování zařízení. Představte si paměťovou sadu dimenzovanou pro provoz na DDR3-1600, 6-6-6-18 (CL-tRCD-tRP-tRAS): Bez dalšího můžeme odhadnout šest cyklů pro přístup na stránku, 12 cyklů pro stránku- prázdný přístup a 18 cyklů pro přístup s chybějící stránkou.
Normalizováno na latenci přístupu při přístupu na stránku, přístup s prázdnou stránkou je dvakrát tak dlouhý a přístup s vynecháním stránky je celý třikrát tak dlouhý. Pokud to zkombinujeme s tím, co víme o vnitřních funkcích stavového automatu SDRAM, uvidíme, že stránka hit a stránka chybí jsou ve skutečnosti jen podmnožiny stejného stavu banky (aktivní). Přístup s prázdnou stránkou samozřejmě nutně znamená nečinnou banku. Následující důkaz nás odměňuje silným vhledem.

Proměnná n také představuje procento přístupů k bankám s otevřenými stránkami, které musí mít za následek přístup s přístupem na stránku, pokud máme jednoduše tempovat nominální přístupovou latenci, které by bylo dosaženo, kdyby každý přístup ke čtení byl do nečinné banky. A jediné, na čem to závisí, je zpoždění RAS Precharge a Row-Column (nebo Command) Delay daného zařízení.
Mysleli byste si, že když budete pracovat na maximalizaci n, bude maximalizován i výkon. A měl bys pravdu. Vezměme to, co jsme se doposud naučili, a posuňme to o stupeň výš. Slibujeme, že poté už nikdy neuvidíte časování vzpomínek ve stejném světle.
Než budete pokračovat, připravili jsme video pro ty z vás, kteří by si chtěli prohlédnout několik jednoduchých animací, které mají pomoci vizualizovat jednotlivé typy transakcí:
Co tím myslíte, že jste nikdy neslyšeli o technologii Adaptive Page Management (APM)? No, to musí být proto, že Intel Marketing, jak se zdá, necítí potřebu to uvádět.
Jednoduše řečeno, APM společnosti Intel na základě potenciálních důsledků nevyřízených paměťových transakcí určuje, zda uzavření otevřených stránek nebo jejich ponechání otevřené déle může být prospěšné pro celkový výkon paměti. V reakci na to se paměťový řadič může (nebo nemusí) rozhodnout vydávat příkazy k uzavření stránek v závislosti na naprogramované operaci.
Obrázek 10 poskytuje obecný tok událostí potřebných pro řízení takového procesu. V našem vysvětlení vám hodláme představit všechna známá nastavení registrů potřebná k úpravě politiky funkčního řízení, ale nejprve musíme podrobně popsat potřebné akce a účel konstrukčních prvků, které tvoří takový mechanismus. Lepší pochopení základní logiky se vám vyplatí, když se pokusíte dosáhnout měřitelných zlepšení výkonu prostřednictvím experimentování.
Podle obrázku 11 transakční fronta ukládá paměťové transakce generované procesorem. Na rozdíl od typické fronty FIFO (First-In-First-Out) s ocasem, do kterého může být vložena paměťová transakce, a hlavou, ze které mohou být paměťové transakce vyskakovány, je tato transakční fronta tvořena množstvím úložných prvků umožňujících jedinou paměť. transakce, které mají být odstraněny ze seznamu a odeslány do paměti v jiném pořadí, než byly původně přidány do fronty.
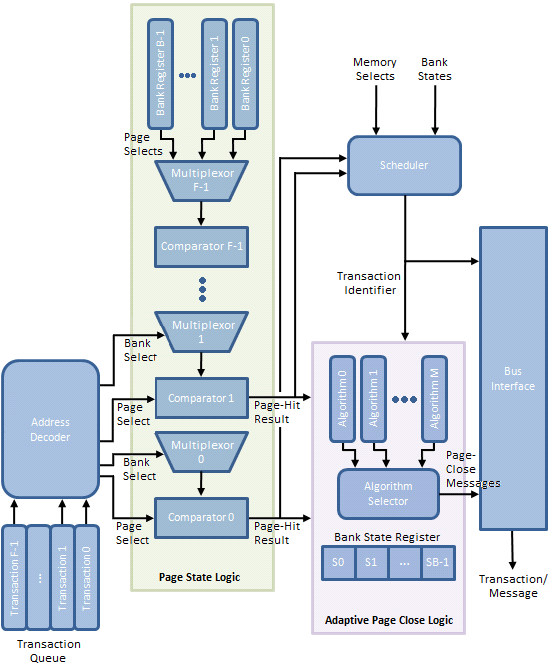
Plánovač, spouštěný logikou stavu stránky, načítá předem identifikované paměťové transakce ve frontě pro opětovné řazení na základě výběru paměti (jak banky, tak stránky) a souvisejících výsledků hledání stránky. Řada bankovních stavových registrů sleduje akce prováděné u každé banky uložením stavového slova, které mimo jiné naznačuje, zda se logika Adaptive Page Close Logic rozhodla zavřít banku v reakci na předchozí paměťovou transakci do stejné banky.
Konečně, na základě zásady vytvořené nástrojem Algorithm Selector, zpráva o zavření stránky buď je, nebo není generována na základě stejných výsledků hledání stránky, registrů bankovních států a výběrů banky/stránky ve snaze zvýšit počet následných přístupy s přístupem na stránku a/nebo snížit počet přístupů s chybějící stránkou.
Okamžitého a hmatatelného zisku je dosaženo za každou úspěšně přeobjednanou transakci, protože přístup na stránku je efektivnější než prázdná stránka nebo v nejhorším případě vynechání stránky. To je vždy případ Core i7 a je to jeden z dobře známých hlavních bodů této architektury. Vypněte Adaptive Page Management (v BIOSu deaktivujte Adaptive Page Closing) a zde proces končí. Stránka může zůstat otevřená po určitou omezenou dobu nebo může být okamžitě uzavřena; nejsme si jisti, protože bez vnitřní pomoci to opravdu nejde vědět.
Adaptivní logika zavírání stránky se nyní musí rozhodnout, zda shromáždí všechny výhry a zavře stránku, nebo ji nechá běžet a nechá ji ještě chvíli otevřenou. Zatímco další přístup s přístupem na stránku může přinést další zisky, špatné „hádání“ způsobí nákladný přístup k vynechání stránky, což by byl pouze přístup s prázdnou stránkou. Kdyby jen existoval nějaký způsob, jak by systém mohl měřit efektivitu předchozích blízkých rozhodnutí a pak upravit politiku tak, aby vyhovovala…
Překvapení! Správce stránek – složený z logiky stavu stránky, adaptivní logiky zavírání stránky a plánovače – dělá přesně to. Jak se tato účinnost měří a jak je výsledek tohoto hodnocení použit k přizpůsobení rozhodovacího procesu, je naším dalším tématem diskuse.
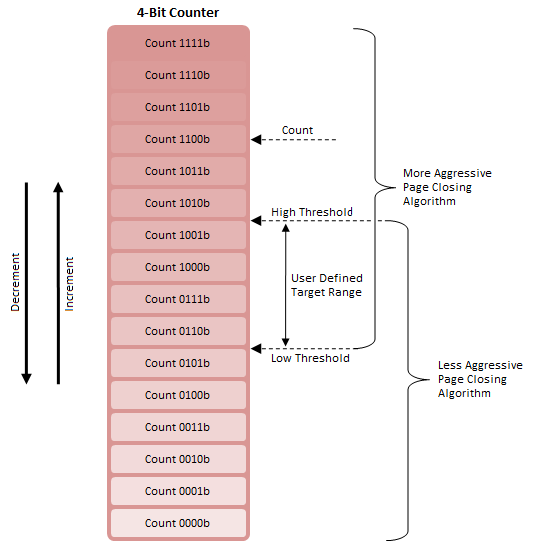
Nejprve zvažte 4bitový čítač se dvěma nastavitelnými prahovými hodnotami (obrázek 12). Když je Počet větší než High Threshold, Algoritmus A je považován za vhodný; totéž platí pro Algoritmus B a počet méně než Low Threshold.
Pro rozsah mezi High Threshold a Low Threshold může být účinný kterýkoli z algoritmů. Důvodem je to, že k přepnutí z algoritmu B na algoritmus A dojde pouze s počtem větším než High Threshold a zvýšením a k přepnutí z Algorithmu A na Algorithm B dojde pouze s Countem menším než Low Threshold a klesajícím.
Rozsah překrytí je také cílový rozsah, protože systém se bude přirozeně snažit udržovat počítadlo mezi těmito dvěma body. To je pravda, protože Algoritmus A má tendenci snižovat počet, zatímco algoritmus B má tendenci počet zvyšovat. Tento systém slouží ke snížení nebo odstranění rychlého přehazování mezi algoritmy.
Dále definujte pravdivostní tabulku (obrázek 13) definující, jak se bude počet lišit. Tímto způsobem můžeme do našeho systému zakódovat mechanismus zpětné vazby. Úspěšné předpovědi pomocí adaptivní logiky zavírání stránky – zabráněný přístup k vynechání stránky (dobré) v reakci na rozhodnutí zavřít stránku nebo usnadněný přístup na stránku (dobrý) v reakci na rozhodnutí nechat stránku otevřenou – navrhněte ne je nutná změna zásad, a proto nikdy neupravujte Count.
Chcete-li usnadnit přístup k vynechání stránky (špatný) kvůli špatnému rozhodnutí nechat stránku otevřenou, zvyšte počet. Pokud by Count měl stoupající trend, mohli bychom dospět k závěru, že současná politika byla nejčastěji nesprávná, a nejen to, měla tendenci nechávat stránky otevřené příliš dlouho, zatímco „lovily“ operace s přístupem na stránku. Aktuální algoritmus nesmí zavírat stránky dostatečně agresivně.
Chcete-li zabránit přístupu k přístupu na stránku (špatný) kvůli špatnému rozhodnutí předčasně zavřít stránku, snižte počet. Pokud by Count měl klesající trend, měli bychom podezření na opak: algoritmus příliš agresivně zavírá stránky a nechává potenciální hity na střižně.

Jak nejlépe můžeme říci, tento konstrukt představuje realitu pro technologii APM. Přestože bychom rádi věřili, že systém má více než dva převody (algoritmy), náš model dokonale vysvětluje existující řídicí registr jak v typu, tak v počtu.
Při pohledu do budoucna uvidíte Max. limit zavření stránky a Minimální limit zavření stránky jsou specifikované hodnoty vysokého a nízkého prahu. Nastavení většího rozdílu zvyšuje velikost pásma necitlivosti zpětné vazby a zpomaluje rychlost, jakou systém reaguje na své vlastní vyhodnocovací úsilí. Mistake Counter je reprezentován počátečním Count a měl by být nastaven někde blízko středu mrtvého pásma.
Adaptivní počítadlo časového limitu nastavuje dobu uplatnění jakéhokoli rozhodnutí ponechat stránku otevřenou (tj. jak dlouho trvá rozhodnutí ponechat stránku otevřenou, než se vzdáme naděje na přístup ke stránce). Opakovaný přístup na stejnou stránku vynuluje tento čítač pokaždé, pokud je zbývající životnost nenulová. Nižší hodnoty mají za následek agresivnější politiku zavření stránky a naopak pro vyšší hodnoty.
Věříme, že sazba požadavků řídí, jak často se aktualizuje Count (počítadlo chyb), a tedy jak hladce se systém přizpůsobuje rychle se měnícímu pracovnímu zatížení. Musí existovat dobrý důvod, proč nenastavit tuto míru přerušení na co nejnižší možnou hodnotu. Možná to vyčerpává hardwarové zdroje potřebné pro jiné operace nebo možná vyšší pracovní cykly neúměrně zvyšují spotřebu energie. Ať už je důvod jakýkoli, existuje více než férová šance, že můžete ublížit výkonu, pokud se s tímto nastavením jen plácáte.
Zde v AnandTech jsme se rozhodli udělat něco navíc pro vás, našeho věrného čtenáře. Před několika týdny jsme se obrátili na technickou podporu ASUS USA s žádostí o zřízení technické konzultace s jejich oddělením Firmware Engineering. Po předání našeho požadavku ze schůzky vzešel speciální beta BIOS, který přidal řadu dříve nedostupných registrů ladění paměti, které byly kdysi vyloučeny z přímé uživatelské kontroly.
V zájmu úplného odhalení jsme požádali o stejnou pomoc od EVGA, a přestože byli ochotni podpořit naši hru, technické potíže jim zabránily dodat vše, v co jsme původně doufali.
Jak je vidět níže, tyto nové registry jsou: Adaptivní zavírání stránky, Adaptivní počítadlo časového limitu, počítadlo požadavků, Maximální limit zavření stránky, Minimální limit zavření stránky a Čítač chyb. Podle podezření se první nastavení používá k úplnému povolení nebo zakázání funkce. Je zajímavé, že Intel se rozhodl tuto funkci ve výchozím nastavení nepovolit; tak to necháme na vás.
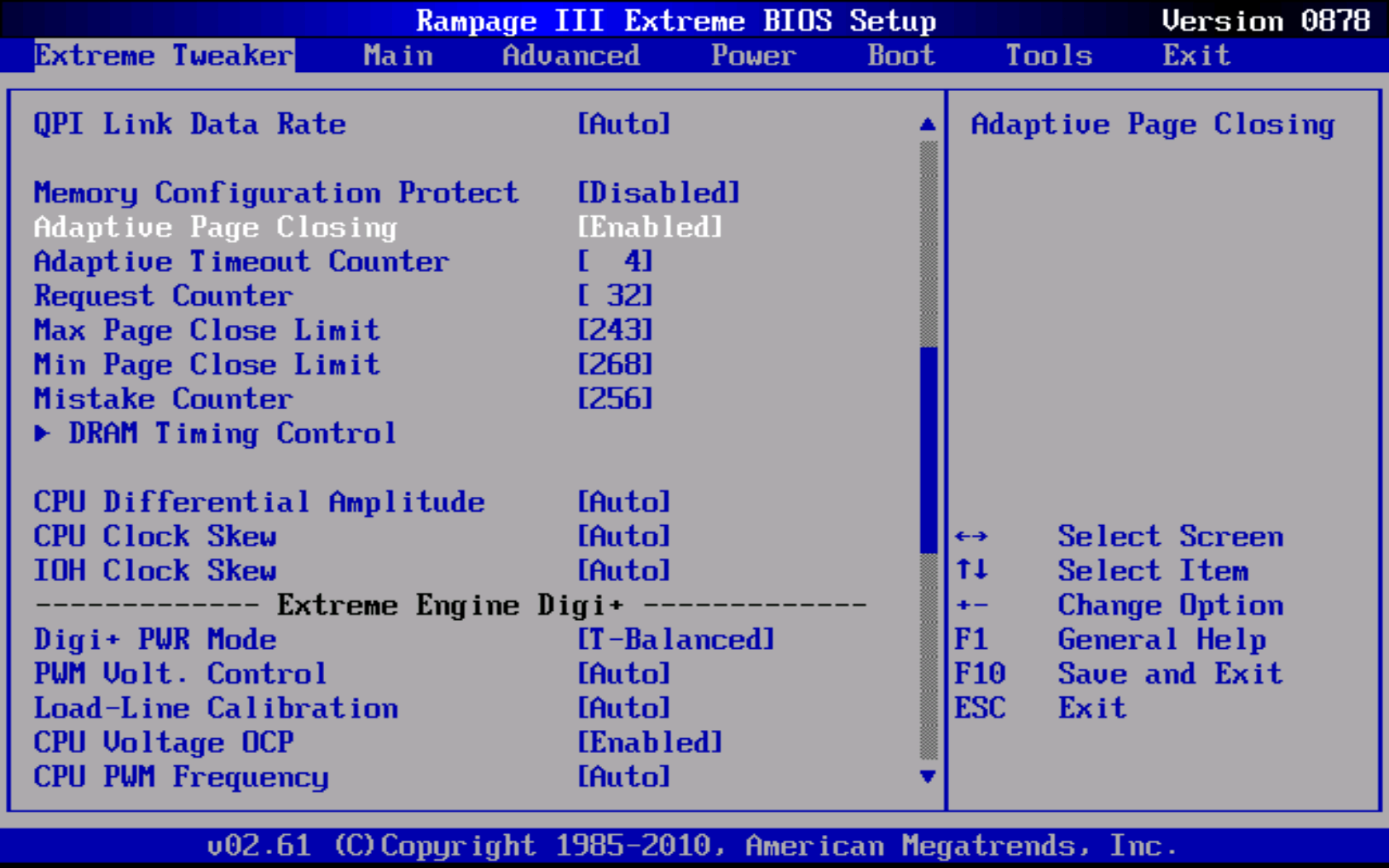
Krátký popis každého registru je uveden níže (převzato z Intel Core i7-900 Desktop Processor Extreme Edition Series a Intel Core i7-900 Desktop Processor Series Datasheet, svazek 2, strana 79, z října 2009). Uvědomte si, že zdroj s největší pravděpodobností obsahuje alespoň jednu známou chybu. Konkrétně Intel poskytl přesně stejný popis pro Adaptive Timeout Counter a Mistake Counter. Také počet bitů pro počítadlo chyb v tabulce neodpovídá hodnotě v textu, což dále naznačuje, že se někdo zbláznil.

Jakmile budete mít čas plně vstřebat výše uvedené informace – a zamyslet se nad tím, jak jsme úžasní – rádi bychom vás srdečně pozvali, abyste provedli nějaké vlastní testování a nahlásili své výsledky na našem fóru. Čtenáři AnandTech s platným přihlášením si nyní mohou stáhnout ASUS Rampage III Extreme BIOS vydání 0878. Ve skutečnosti jsme neměli příležitost provést žádné významné experimenty s tím málo volným časem, který máme, a potřebujeme vaši pomoc při průzkumu neprobádaného území…
Doufáme, že jste si čtení tohoto článku užili stejně jako my jeho sestavování. Pokud jste si našli čas na důkladné prostudování a strávení informací v rámci spletitosti základní operace s pamětí, už by to nemělo být tak matoucí téma. Vzhledem k tomu, že základní práce ustoupily z cesty, máme nyní pevnou platformu, ze které můžeme stavět, protože začínáme podrobněji zkoumat další cesty ke zvýšení výkonu paměti. Již jsme určili další témata, která stojí za to prodiskutovat, a pokud se v knihách objeví čas, plánujte vám přinést další.
Předpokládá se, že jedna velká otázka může zůstat: Jaké jsou skutečné výhody ladění paměti? Technicky jsme se tomuto tématu podrobně věnovali minulý rok v předchozím článku. Doporučujeme, abyste si ji ještě jednou pro připomenutí přečetli, než se pustíte do jakékoli cesty s přetaktováním (nebo než budete spěchat přehnaně utrácet za paměťové sady). Vše napsané v tom článku tehdy platí stejně i dnes. Provedli jsme zde testy na našich vzorcích z Gulftownu a zjistili jsme přesně stejné chování. Společnost Intel nepochybně podnikla kroky, aby zajistila, že jejich architektury nebudou předčasně zablokovány tím, že paměťovému řadiči poskytne velkou tlustou sběrnici pro komunikaci s moduly DIMM.

Z toho, co můžeme říci, příští generace výkonných procesorů od Intelu přejde na 256bitový (čtyřkanálový) paměťový řadič, takže nebude potřeba příliš vysokofrekvenčních paměťových sad. Znovu tedy opakujeme něco, co již mnozí řekli: nejvyšší prioritou, pokud jde o zlepšování paměťových integrovaných obvodů a jejich příslušných architektur, by mělo být zaměřit vývoj na snížení absolutních minimálních požadavků na latenci pro časování, jako jsou CAS a tRCD, spíše než honbu za syrovou syntetickou šířkou pásma. čísla nebo nastavení přímých frekvenčních záznamů na úkor nepřiměřeně vysokých časů náhodného přístupu.
Když se na chvíli vzdálíme od segmentu výkonu, něco jiného, co také vyšlo na světlo, se říká, že architektura Sandy Bridge od Intelu (v 1. čtvrtletí 2011) záměrně omezí přetaktování řízené referenčními hodinami u běžných dílů na 5 % nad provozní frekvenci skladu. . Pokud tomu tak skutečně je, bude to mít za následek velmi omezenou schopnost ovládat frekvenci paměťové sběrnice s omezenou granularitou pro vyladění prvních 50~70 MHz za každým krokem, po kterém následuje povinný minimální skok o 200 MHz na další provozní úroveň. Přístup ke skrytému potenciálu bude ještě obtížnější, zejména pro uživatele běžných paměťových sad. I když to z hlediska zpracování nemá žádnou nevýhodu (hej, vyšší rychlost je vždy lepší), může to být další vážný hřebík do rakve již slábnoucího odvětví přetaktování pamětí.
Zdroj
Everything You Always Wanted to Know About SDRAM (Memory): But Were Afraid to Ask
by Rajinder Gill on August 15, 2010 10:59 PM EST